
文章目录
- 02-PDI(Kettle)导入与导出
-
- 多个excel表格数据的合并
-
- 实验步骤:
- 拓展 Excel介绍
- 基于文本的数据导入与导出
-
- 实验步骤
- 扩展 回车与换行的区别
- 基于XML文本的数据导入导出
-
- 步骤设计
- 扩展 XML教程
- 基于JSON文本的数据导入导出
-
- 实验步骤
- 拓展 JSON
- 基于数据库的数据导入与导出
-
- 实验步骤
- 拓展 kettle分享数据库连接
02-PDI(Kettle)导入与导出
本文主要介绍基于Kettle的导入与导出,并针对每种文件特点进行相关介绍。
多个excel表格数据的合并
实验步骤:
- 数据准备:
在课程信息表1.xlsx中的sheet1中提供如下数据,
 将该文件复制几份,放在不同的子目录下,本文的目录数据结果如下:
将该文件复制几份,放在不同的子目录下,本文的目录数据结果如下:
D:\kettle-XXX-data\多个Excel合并data>tree . /f /a
卷 软件 的文件夹 PATH 列表
D:\KETTLE-REPOSITORY-DATA\CHAPTER03-1-02多个EXCEL合并DATA
| 课程信息表1.xlsx
| 课程信息表2.xlsx
| 课程信息表3.xlsx
|
\---子目录课程信息表4.xlsx-
设计转换

-
命名参数的配置。
在画布上点击鼠标右键,在弹出的菜单中选择“Properties”调出命名参数设置窗口。
选择卡项“paramerers”配置命名参数,其中“Default Value”的值为待处理的输入数据的实际存储路径。

-
““Microsoft Excel input”的配置:
Files选项设置:
数据源的 配置如下图所示:(如果该文件夹下包含有子目录,则“包含子目录”配置为”Y”)

sheet选项设置:
数据表和数据行列的的选择如下图配置:
 Fields选项设置:
Fields选项设置:
重新配置数据的字段,如下图所示。

-
“Microsoft Excel 输出”的配置
配置输出的文件名,Excel版本,sheet等,如下图所示。
 配置输出的字段名,如下图所示。
配置输出的字段名,如下图所示。

-
运行转换
依次点击菜单“Action->run”运行程序.运行完毕后,如下图所示,

点击“Preview data”浏览输出数据,亦可在实验输出路径上查看验证输出的Excel文件数据,已经合并成了一个Excel文件。

拓展 Excel介绍
最大行 1048576
最大列 列从A开始,Z结尾,XFD等同于26进制的O64 XFD是26进制的(24*26+6)*26+4=16384…也就是2^14 =16384
按住下键9小时得出的吧。其实用Ctrl+下,一次就到最后一行了。1048576好啊,这个数多整,1024×1024。对学计算机的人来说,256、1024、2^16=65536、1048576,这些都是很整很整的数。
Excel 规范与限制
https://support.microsoft.com/zh-cn/office/excel-%e8%a7%84%e8%8c%83%e4%b8%8e%e9%99%90%e5%88%b6-1672b34d-7043-467e-8e27-269d656771c3?ui=zh-cn&rs=zh-cn&ad=cn#ID0EDBD=Newer_versions
基于文本的数据导入与导出
文本文件是使用ETL工具处理的最简单的一种数据。文本文件易于交换,压缩比高,任何文本编辑器都可打开。总体来说,文本文件可分为分割符文件和固定宽度文件。
本实验读入student.csv文件,输出固定宽度为15字节的student.txt文件。student.csv文件以逗号为分隔符。
实验步骤
- 数据准备:
student.csv的内容
cat student.csv
学号,姓名,性别,班级,年龄,成绩,身高,手机
1,张一,男,1701,16,78,170,18946554571
2,李二,男,1701,17,80,175,18946554572
3,谢逊,男,1702,18,95,169,18946554573
4,赵玲,女,1702,19,86,180,18956257895
5,张明,男,1704,20,85,185,18946554575
6,张三,女,1704,18,92,169,18946554576
- 设计转换图。
如下:

- “CSV file input”步骤的设置
(1)点击“Browse(B)浏览”按钮,选择student.csv文件作为输入文件来处理。
(2)“Delimiter列分隔符”选择逗号(,),CSV文件默认是逗号分割。
(3)勾选“Header row present 包含列头行”,表示此文件内含有文件头(列名)
(4)中文乱码可选择“File encoding 文件编码”为UTF-8
(5)点击“Get Fields获取字段”,在此步骤的字段列表中选择出此文件的8个字段。
csv input 注意事项
 如果输出为等宽文本,需要在获取字段后,修改所有字段的类型为string。
如果输出为等宽文本,需要在获取字段后,修改所有字段的类型为string。
- “Text file output”步骤的设置
File选项设置:
(1)点击“Browse(B)浏览”按钮,选择等宽文件的输出路径。
(2)文件的后缀名在“extension 扩展名”中指定txt。
Content选项设置:
(3)“separator分隔符”配置为空,因为我们需要输出没有分隔符的文件。
(4)“Format格式”选择“LF terminated(Unix)”或“CR+LF terminated(window,DOS)”。
Fileds选项设置:
(5)点击“Get Fields获取字段”按钮,在字段列表上选择出此文件的所有字段。然后,在各个字段的“长度”中,输入“15”,表示每个输出字段的长度为15字节。

- 点击运行按钮运行转换。
输出文件输出文件.txt内容如下:

扩展 回车与换行的区别
转载于:http://www.pythontab.com/html/2017/linuxkaiyuan_0115/1116.html
关于换行和回车其实平时我们不太在意,所以关于两者的区别也不太清楚,在平时开发时可能会遇到一些文件处理的问题,放到不同的操作系统上出现各种坑。那么回车和换行到底有哪些区别呢?今天咱们就来总结一下。
- 由来
在计算机还没有出现之前,有一种叫做电传打字机(Teletype Model 33)的机械打字机,每秒钟可以打10个字符。但是它有一个问题,就是打完一行换行的时候,要用去0.2秒,正好可以打两个字符。要是在这0.2秒里面,又有新的字符传过来,那么这个字符将丢失。

于是,研制人员想了个办法解决这个问题,就是在每行后面加两个表示结束的字符。一个叫做“回车”,告诉打字机把打印头定位在左边界,不卷动滚筒;另一个叫做“换行”,告诉打字机把滚筒卷一格,不改变水平位置。
这就是“换行”和“回车”的由来。
- 使用
后来,计算机发明了,这两个概念也就被般到了计算机上。那时,存储器很贵,一些科学家认为在每行结尾加两个字符太浪费了,加一个就可以。于是,就出现了分歧。
回车 \r 本义是光标重新回到本行开头,r的英文return,控制字符可以写成CR,即Carriage Return
换行 \n 本义是光标往下一行(不一定到下一行行首),n的英文newline,控制字符可以写成LF,即Line Feed
符号 ASCII码 意义
\n 10 换行NL (0x0A)
\r 13 回车CR (0x0D)
\r\n (0x0D,0x0A)
在不同的操作系统这几个字符表现不同,比如在WIN系统下,这两个字符就是表现的本义,在UNIX类系统,换行\n就表现为光标下一行并回到行首,在MAC上,\r就表现为回到本行开头并往下一行,至于ENTER键的定义是与操作系统有关的。通常用的Enter是两个加起来。
不同操作系统下的含义:
\n: UNIX 系统行末结束符
\r\n: window 系统行末结束符
\r: MAC OS 系统行末结束符
我们经常遇到的一个问题就是,Unix/Mac系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix/Mac下打开的话,在每行的结尾可能会多出一个^M符号。
后来,Mac 改成跟Unix/Linux 一样的“\n”
“first line\rsecond line” 的效果是:
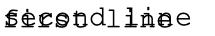
“first line\nsecond line” 的效果是:

只有 “first line\r\nsecond line” 才能展示成:

计算机时代改用计算机之后,该怎么办呢?早期的 ADM-3A 计算机的键盘有人觉得还是保留原来打字机的习惯,继续用 CR LF (\r\n),例如 MS-DOS 操作系统,再比如网络协议。 Windows 自然也是沿用 MS-DOS 的传统。有人觉得计算机没有必要保留打字机的旧习惯,留下一个就够了。这其中又有人用 LF (\n),例如 Unix 也有人用 CR (\r),例如 Mac OS 经典操作系统(Mac OS 9 以及之前)。后来 Mac OS X 也把 Mac OS 9 的规矩废除了,投奔Unix,所以改成用 LF (\n)。今天,我们看到的就是 Windows 与网络协议都用 CR LF ,而类 Unix 操作系统都用 LF 。
- 软回车和硬回车
再扩展一下回车的一些知识。
硬回车就是普通我们按回车产生的,它在换行的同时也起着段落分隔的作用。
软回车是用 Shift + Enter 产生的,它换行,但是并不换段,即前后两段文字在 Word 中属于同一“段”。在应用格式时你会体会到这一点。
软回车能使前后两行的行间距大幅度缩小,因为它不是段落标记,要和法定的段落标记——硬回车区别出来。硬回车的html代码是
…
,段落的内容就夹在里面,而软回车的代码很精悍:
。网页的文字如果复制到word中,则硬回车变为弯曲的箭头,软回车变为向下的箭头。
基于XML文本的数据导入导出
步骤设计
- 准备数据
<?xml version='1.0' encoding='UTF-8'?>
<CATALOG>
<CD>
<TITLE>Empire Burlesque</TITLE>
<ARTIST>Bob Dylan</ARTIST>
<COUNTRY>USA</COUNTRY>
<COMPANY>Columbia</COMPANY>
<PRICE>10.90</PRICE>
<YEAR>1985</YEAR>
</CD>
<CD>
<TITLE>Hide your heart</TITLE>
<ARTIST>Bonnie Tyler</ARTIST>
<COUNTRY>UK</COUNTRY>
<COMPANY>CBS Records</COMPANY>
<PRICE>9.90</PRICE>
<YEAR>1988</YEAR>
</CD>
<CD>
<TITLE>Greatest Hits</TITLE>
<ARTIST>Dolly Parton</ARTIST>
<COUNTRY>USA</COUNTRY>
<COMPANY>RCA</COMPANY>
<PRICE>9.90</PRICE>
<YEAR>1982</YEAR>
</CD>
<CD>
<TITLE>Still got the blues</TITLE>
<ARTIST>Gary Moore</ARTIST>
<COUNTRY>UK</COUNTRY>
<COMPANY>Virgin records</COMPANY>
<PRICE>10.20</PRICE>
<YEAR>1990</YEAR>
</CD>
</CATALOG>
- 转换步骤设计如下:

- Get data from XML设置
将文件添加到选择文件区域
 选择get xpath nodes
选择get xpath nodes
 设置fileds
设置fileds

- Excel输出设置
这里先不描述
- XML output设置

- 输出的文件为:
<?xml version='1.0' encoding='UTF-8'?>
<CATALOG>
<CD><TITLE>Empire Burlesque</TITLE> <ARTIST>Bob Dylan</ARTIST> <COUNTRY>USA</COUNTRY> <COMPANY>Columbia</COMPANY> <PRICE>10.9</PRICE> <YEAR>1985</YEAR></CD>
...
<CD><TITLE>Still got the blues</TITLE> <ARTIST>Gary Moore</ARTIST> <COUNTRY>UK</COUNTRY> <COMPANY>Virgin records</COMPANY> <PRICE>10.20</PRICE> <YEAR>1990</YEAR></CD>
</CATALOG>
扩展 XML教程
内容较多,参考
http://www.jk1123.com/?p=124
https://blog.csdn.net/L_ZG_/article/details/105363109
基于JSON文本的数据导入导出
实验步骤
- 准备数据
本案例数据位于:XX\read-nested-fields.js
内容如下:
{"missions":[{"id": "59434767","timestamp": "2011-11-21 09:21:53","data": [{"field": "13776121","value": "Baylor Dallas"},{"field": "13776401","value": "CHF"},{"field": "13777966","value": "John Doe"},{"field": "13780027","value": "9999"} ]},{"id": "59474875","timestamp": "2011-11-21 17:01:22","data": [{"field": "13776121","value": "Healthsouth,"},{"field": "13776401","value": "Pneumonia"},{"field": "13777966","value": "Jane Doe"} ]}],"total": 2,"pages": 1}
- 步骤设计
转换步骤设计如下:

- json input 设置
File选项设置:
设置文件地址:XX\read-nested-fields.js
content选项设置为默认设置
fields选项设置:
id $.missions…id 中$表示json数据,.missions…id表示获取该文件中missions下的子元素的中的id子元素。
data $.missions…data 中$表示json数据,.missions…data表示获取该文件中missions下的子元素的中的data子元素。

-
json input get -nested fields设置
File选项设置:
勾选source is from previous step,表示选择读取上一步骤的源字段
select field:会自动提示上一步骤中的data和id字段,这里勾选data字段。

fileds选项设置

-
excel output设置
与前面基本类似,重点在于设置字段选择 -
json out put 设置

拓展 JSON
JSON格式相关
https://www.bejson.com/
基于数据库的数据导入与导出
实验步骤
当前,市场上主流的关系型数据库有MySQL、Oracle、SQL Server、DB2等。面对这些类型的关系型数据库,Kettle都可以使用“表输入”“表输出”这两个步骤完成数据的导入与导出。
本实验读入student表数据,输出满足身高大于等于170,成绩大于等于80的学生数据。输出的数据存储在StuOut表中。
1.在mysql命令行执行student.sql脚本脚本内容
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (`学号` int(11) NOT NULL,`姓名` varchar(45) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`性别` varchar(45) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`班级` varchar(45) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`年龄` varchar(45) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`成绩` int(15) NULL DEFAULT NULL,`身高` varchar(45) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`手机` varchar(45) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,PRIMARY KEY (`学号`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '张一', '男', '1701', '16', 78, '170', '18946554571');
INSERT INTO `student` VALUES (2, '李二', '男', '1701', '17', 80, '175', '18946554572');
INSERT INTO `student` VALUES (3, '谢逊', '男', '1702', '18', 95, '169', '18946554573');
INSERT INTO `student` VALUES (4, '赵玲', '女', '1702', '19', 86, '180', '18956257895');
INSERT INTO `student` VALUES (5, '赵明', '男', '1704', '20', 85, '185', '18946554575');
INSERT INTO `student` VALUES (6, '张三', '女', '1704', '18', 92, '169', '18946554576');SET FOREIGN_KEY_CHECKS = 1;
执行脚本
source /home/ubuntu/student.sql
2.新建转换如下

- data grid设置

- table input设置
创建mysql_conn连接,并测试
 测试完成后,执行Get SQL select statement
测试完成后,执行Get SQL select statement
修改sql语句,添加
WHERE 身高>? AND 成绩>?
这一步骤需要勾选Replace variables in,并选择insert data from step选择上一步骤的data grid。
完整SQL为:
SELECT学号
, 姓名
, 性别
, 班级
, 年龄
, 成绩
, 身高
, 手机
FROM student
WHERE 年龄 >? AND 成绩 > ?
- table output
选择target后,可以执行下sql
 执行sql后,可以映射字段
执行sql后,可以映射字段

注意:这里可以多次尝试,比如去掉specify database fields,get fields ,table field的字段可以手动选择。
拓展 kettle分享数据库连接
先在一个转换中创建连接后,通过view – 》database connections –》 数据库连接–》share就可以分享了
