
DENSE 数据集 – STF 数据集 – Seeing Through Fog Without Seeing Fog: Deep Multimodal Sensor Fusion in Unseen Adverse Weather(CVPR 2020)
- 摘要
- 1. 引言
- 2. 相关工作
- 3. 多模式恶劣天气数据集
-
- 3.1 多模态传感器设置
- 3.2 记录
- 4. 自适应深度融合
-
- 4.1 自适应多模态单发融合
- 4.2 熵导向融合
- 4.3 损失函数和训练详情
- 5. 评估
- 6. 结论和未来工作
- References
- 补充材料
- 1. 附加的数据集详细信息
-
- 1.1 数据预选流程
- 1.2 数据注释流程
- 1.3 受控天气数据集
- 2. 附加定性检测结果
- 3. 附加训练详情
-
- 3.1 锚框
- 3.2 图像同态
- 3.3 单个传感器的贡献
- 3.4 激光雷达输入表示
- 3.5 运行时评估
- 4. 附加域适配结果
-
- 4.1 附加特征适配结果
- 4.2 附加数据集适配结果
- 4.3 附加语义适应结果
- 5. 附加模拟结果
-
- 5.1 雾中的强度成像
- 5.2 雾中的脉冲激光雷达
- 5.3 雾中的门控成像
- 5.4 雾中的雷达测量
- 5.5 附加模拟增强检测结果
- 6. 附加的仅图像检测结果
- References
声明:此翻译仅为个人学习记录
文章信息
- 标题:Seeing Through Fog Without Seeing Fog: Deep Multimodal Sensor Fusion in Unseen Adverse Weather (CVPR 2020)
- 作者:Mario Bijelic, Tobias Gruber, Fahim Mannan, Florian Kraus, Werner Ritter, Klaus Dietmayer, Felix Heide
- 文章链接:https://openaccess.thecvf.com/content_CVPR_2020/papers/Bijelic_Seeing_Through_Fog_Without_Seeing_Fog_Deep_Multimodal_Sensor_Fusion_CVPR_2020_paper.pdf
- 补充材料:https://www.cs.princeton.edu/~fheide/AdverseWeatherFusion/figures/AdverseWeatherFusion_Supplement.pdf
数据集简介
- 数据集官网:https://www.uni-ulm.de/en/in/driveu/projects/dense-datasets
- 数据集开发工具包:https://github.com/princeton-computational-imaging/SeeingThroughFog
- 官方下载地址:https://www.uni-ulm.de/en/in/driveu/projects/dense-datasets/dense-registration-form/
摘要
多模态传感器流(如相机、激光雷达和雷达测量)的融合在自动驾驶车辆的目标检测中起着关键作用,自动驾驶车辆基于这些输入做出决策。虽然现有的方法在良好的环境条件下利用冗余信息,但它们在恶劣的天气下会失败,因为在这种天气下,传感器流可能会不对称地扭曲。这些罕见的“边缘情况”场景没有在可用的数据集中表示,现有的融合架构也没有设计来处理它们。为了应对这一挑战,我们提出了一个新的多模式数据集,该数据集在北欧行驶超过10000公里后采集。尽管该数据集是第一个在恶劣天气下的大型多模态数据集,为激光雷达、相机、雷达和门控近红外传感器提供了100k标签,但由于极端天气很少,因此它不利于训练。为此,我们提出了一种用于鲁棒融合的深度融合网络,无需覆盖所有不对称失真的大量标记训练数据。从提案级融合出发,我们提出了一种单发模型,该模型由测量熵驱动,自适应地融合特征。我们在广泛的验证数据集上验证了所提出的方法,该方法基于干净的数据进行了训练。代码和数据提供在https://github.com/princeton-computational-imaging/SeeingThroughFog。
1. 引言
目标检测是自动驾驶机器人(包括自动驾驶车辆和自动驾驶无人机)的一个基本计算机视觉问题。此类应用需要在具有挑战性的真实场景中使用场景目标的2D或3D边界框,包括复杂的杂乱场景、高度变化的照明和恶劣的天气条件。最有前途的自动驾驶汽车系统依赖于多传感器模态的冗余输入[59,6,74],包括相机、激光雷达、雷达和FIR等新兴传感器[30]。越来越多的使用卷积神经网络进行目标检测的工作使得能够从这种多模态数据中进行精确的2D和3D框估计,通常依赖于相机和激光雷达数据[65,11,57,72,67,43,36]。虽然这些现有的方法以及对其输出进行决策的自主系统在正常成像条件下表现良好,但在恶劣天气和成像条件下它们会失败。这是因为现有的训练数据集偏向于晴朗的天气条件,并且检测器架构被设计为仅依赖于未失真的传感器流中的冗余信息。然而,它们不是为不对称地扭曲传感器流的苛刻场景而设计的,见图1。极端天气条件在统计上是罕见的。例如,只有在北美0.01%的典型驾驶过程中才能观察到浓雾,即使在雾区,能见度低于50米的浓雾每年也只出现15次[62]。图2显示了在瑞典冬季四周内行驶10000公里获得的真实驾驶数据分布。自然偏态分布验证了恶劣天气场景在可用数据集中很少出现,甚至根本没有出现[66,19,59]。不幸的是,域自适应方法[45,29,42]也没有提供特别的解决方案,因为它们需要目标样本,并且通常情况下,恶劣天气扭曲数据的代表性不足。此外,现有方法仅限于图像数据,而不限于多传感器数据,例如包括激光雷达点云数据。

图1.现有的目标检测方法,包括有效的单发检测器(SSD)[41],是在偏向于良好天气条件的汽车数据集上训练的。虽然这些方法在良好的条件下工作良好[19,59],但它们在罕见的天气事件中失败(顶部)。只有激光雷达的检测器,例如在投影激光雷达深度上训练的相同SSD模型,可能会由于雾或雪中的严重反向散射而失真(中心)。这些不对称失真对依赖冗余信息的融合方法来说是一个挑战。所提出的方法(底部)学习如何处理多模态数据中未见过的的(潜在的不对称)失真,在不看到这些罕见场景的训练数据的情况下。
由于现有训练数据集中的传感器输入有限[66,19,59],现有的融合方法主要针对激光雷达相机设置[65,11,43,36,12]。由于训练数据的偏差,这些方法不仅在恶劣天气下与传感器失真作斗争。它们要么在独立处理单个传感器流[12]后通过滤波执行后期融合,要么融合提议[36]或高级特征向量[65]。这些方法的网络架构是在假设数据流是一致和冗余的情况下设计的,即,一个传感器流中出现的目标也出现在另一个传感器中。然而,在恶劣的天气条件下,如雾、雨、雪或极端照明条件下,包括低光或低反射率目标,多模态传感器配置可能会不对称失效。例如,传统的RGB相机在低光场景区域提供不可靠的噪声测量,而扫描激光雷达传感器使用主动照明提供可靠的深度。在雨和雪中,小颗粒通过反向散射对彩色图像和激光雷达深度估计产生同等影响。相反,在雾或雪的条件下,由于反向散射,最先进的脉冲激光雷达系统被限制在20米以内,见图3。虽然依靠激光雷达测量可能是夜间驾驶的一种解决方案,但它不适用于恶劣的天气条件。
在这项工作中,我们提出了一种用于恶劣天气(包括雾、雪和大雨)中目标检测的多模态融合方法,而无需为这些场景提供大量注释训练数据集。具体而言,我们通过脱离现有的提议级融合方法来处理相机、激光雷达、雷达和门控NIR传感器流中的不对称测量损坏:我们提出了一种自适应单发深度融合架构,该架构在交织的特征提取器块中交换特征。这种深度早期融合是由测量的熵控制的。所提出的自适应融合允许我们学习跨场景通用的模型。为了验证我们的方法,我们通过引入在北欧三个月采集的新的多模态数据集来解决现有数据集中的偏差。该数据集是第一个在恶劣天气下的大型多模式驾驶数据集,为激光雷达、相机、雷达、门控近红外传感器和FIR传感器提供了100k标签。尽管天气偏差仍然不可能训练,但该数据允许我们验证所提出的方法在基于干净数据进行训练的同时,能够鲁棒地推广到具有不对称传感器损坏的未见过的天气条件。
具体而言,我们做出以下贡献:
-
我们引入了一个多模式恶劣天气数据集,包括摄像机、激光雷达、雷达、门控NIR和FIR传感器数据。该数据集在北欧行驶超过10000公里,包含了的罕见场景,如大雾、大雪和大雨。
-
我们提出了一种深度多模态融合网络,它不同于提案级融合,而是由测量熵驱动的自适应融合。
-
我们在所提出的数据集上评估了模型,验证了它概括为看不见的不对称失真。该方法在恶劣场景中不受天气影响(包括轻雾、浓雾、雪和晴朗条件),性能优于最先进的融合方法,超过8%AP,并且实时运行。
2. 相关工作
恶劣天气条件下的检测。在过去十年中,汽车数据集[5,14,19,16,66,9]的开创性工作为汽车目标检测[11,8,65,36,41,20],深度估计[18,40,21],车道检测[27],交通灯检测[33],道路场景分割[5,2]和端到端驾驶模型[4,66]提供了肥沃的土壤。尽管现有数据集为这一研究领域提供了支持,但由于地理位置[66]和捕获的季节[19],它们偏向于良好的天气条件,因此缺乏罕见的雾、大雪和雨带来的严重失真。最近的一些研究探索了在这种恶劣条件下仅使用相机的方法[52,7,1]。然而,这些数据集非常小,捕获的图像不到100张[52],仅限于相机视觉任务。相比之下,现有的自动驾驶应用依赖于多模态传感器堆栈,包括摄像头、雷达、激光雷达和新兴传感器,如门控NIR成像[22,23],并且必须在数千小时的驾驶过程中进行评估。在这项工作中,我们填补了这一空白,并引入了一个大规模的评估集,以便为这种多模态输入开发一个对未知失真具有鲁棒性的融合模型。
恶劣天气下的数据预处理。大量工作探索了在处理之前消除传感器失真的方法。特别是从传统强度图像数据中去除雾和霾已经被广泛探索[68,71,34,54,37,7,38,47]。雾会导致对比度和颜色的距离相关损失。除雾方法不仅被建议用于显示应用[25],还被建议作为预处理,以提高下游语义任务的性能[52]。现有的雾和霾去除方法依赖于潜在清晰图像和深度上的场景先验来解决不适定恢复。这些先验是手工制作的[25],分别用于深度和传输估计,或者作为可训练端到端模型的一部分共同学习[38,32,73]。已经为摄像机驾驶员辅助系统提出了雾和能见度估计的现有方法[58,60]。图像恢复方法也已应用于去噪[10]或去模糊[37]。
域自适应。另一项研究通过域自适应处理未标记数据分布的变化[61,29,51,28,70,63]。此类方法可用于使清晰标记的场景适应苛刻的恶劣天气场景[29]或通过特征表示的适应[61]。不幸的是,这两种方法都难以概括,因为与现有的域转移方法相比,一般来说,天气扭曲的数据,而不仅仅是标签数据,代表性不足。此外,现有方法不处理多模态数据。
多传感器融合。自动驾驶车辆中的多传感器馈电通常被融合,以利用测量中的变化线索[44],简化路径规划[15],在存在失真的情况下允许冗余[48],或解决联合视觉任务,如3D目标检测[65]。现有的全自动驾驶传感系统包括激光雷达、摄像头和雷达传感器。由于大型汽车数据集[66,19,59]涵盖有限的传感器输入,现有的融合方法主要针对激光雷达相机设置[65,56,11,36,43]。AVOD[36]和MV3D[11]等方法结合了相机和激光雷达的多个视图来检测目标。它们依赖于合并的感兴趣区域的融合,因此按照流行的区域提案架构执行后期特征融合[50]。在另一项研究中,Qi等人[49]和Xu等人[65]提出了一种管道模型,该模型需要摄像机图像的有效检测输出和从激光雷达点云提取的3D特征向量。Kim等人[35]提出了摄像机激光雷达融合的门控机制。在所有现有方法中,传感器流在特征提取阶段被单独处理,我们表明这阻止了学习冗余,事实上,在存在不对称测量失真的情况下,其性能比单个传感器流更差。
3. 多模式恶劣天气数据集
为了评估恶劣天气中的目标检测,我们获取了一个大型汽车数据集,该数据集为多模态数据提供了2D和3D检测边界框,并对罕见恶劣天气情况下的天气、照明和场景类型进行了精细分类。表1将我们的数据集与最近的大型汽车数据集进行了比较,如Waymo[59]、NuScenes[6]、KITTI[19]和BDD[69]数据集。与[6]和[69]相比,我们的数据集不仅包含了在天气条件下的实验数据,还包含了在大雪、雨和雾中的实验数据。补充材料中给出了注释程序和标签规范的详细说明。通过对多模态传感器数据的跨天气注释和广泛的地理采样,它是唯一允许评估我们的多模态融合方法的现有数据集。未来,我们设想研究人员在现有数据集未涵盖的天气条件下开发和评估多模态融合方法。

表1. 提出的多模态恶劣天气数据集与现有汽车检测数据集的比较。
在图2中,我们绘制了提议数据集的天气分布。通过以0.1Hz的帧速率手动注释所有同步帧来获得统计数据。当能见度分别低于1公里[46]和100米时,我们指导人类注释员区分光线和浓雾。如果雾与降水一起出现,则根据环境道路条件,场景被标记为下雪或下雨。在我们的实验中,我们结合了雪和雨的条件。注意,统计数据验证了恶劣天气下场景的罕见性,这与[62]一致,并证明了在评估真正的自动驾驶车辆时获取此类数据的困难性和关键性,即没有地理围栏区域外的远程操作员的交互。我们发现,极端恶劣的天气条件只发生在局部,而且变化很快。
个别天气条件导致各种传感器技术的非对称扰动,导致非对称退化,即不是所有传感器输出都受到恶化环境条件的影响,而是一些传感器比其他传感器退化更严重,见图3。例如,传统的被动相机在白天条件下表现良好,但在夜间条件或具有挑战性的照明设置(如低太阳照度)下,其性能会下降。同时,激光雷达和雷达等主动扫描传感器受环境光变化的影响较小,这是由于主动照明和检测器侧的窄带通。另一方面,主动激光雷达传感器因雾、雪或雨等散射介质而严重退化,从而限制了雾密度低于50米至25米时的最大可感知距离,见图3。毫米波雷达波在雾中不会强烈散射[24],但目前只能提供低方位分辨率。最近的门控图像显示了在恶劣天气下的鲁棒感知[23],提供了高空间分辨率,但与标准成像器相比缺少颜色信息。由于每个传感器的这些特定弱点和优势,多模态数据在鲁棒检测方法中至关重要。

图2. 右图:德国、瑞典、丹麦和芬兰为期两个月、10000公里的数据收集活动的地理范围。左上:测试车辆设置,包括顶部安装的激光雷达、带闪光灯照明的门控摄像头、RGB摄像头、专用雷达、FIR摄像头、气象站和道路摩擦传感器。左下:整个数据采集过程中的天气状况分布。驾驶数据与天气条件高度不平衡,仅包含恶劣条件作为罕见的样本。

图3. RGB摄像机、扫描激光雷达、门控摄像机和雷达在浓雾中的多模态传感器响应。第一行显示了晴朗条件下的参考记录,第二行显示了能见度为23 m的雾中的记录。
3.1 多模态传感器设置
为了获取数据,我们为测试车辆配备了覆盖可见光、毫米波、近红外和FIR波段的传感器,见图2。我们测量强度、深度和天气状况。
立体摄像机。作为可见波长RGB相机,我们使用两个前向高动态范围汽车RCCB相机的立体对,包括两个分辨率为1920×1024、基线为20.3cm和12位量化的On Semi-AR0230成像器。摄像机以30 Hz的频率运行,并同步进行立体成像。使用焦距为8mm的Lensagon B5M8018C光学器件,获得了39.6°×21.7°的视场。
门控摄像头。我们使用BrightwayVision BrightEye相机在808nm的NIR波段捕获门控图像,该相机工作频率为120 Hz,分辨率为1280×720,比特深度为10比特。该相机提供与31.1°×17.8°立体相机相似的视野。门控成像器依赖于时间同步相机和泛光闪光激光源[31]。激光脉冲发出一个可变的窄脉冲,相机在可调整的延迟后捕捉激光回波。这能够显著减少恶劣天气下颗粒物的反向散射[3]。此外,高成像器速度能够捕获具有不同距离强度分布的多个重叠切片,编码多个切片之间的可提取深度信息[23]。在[23]之后,我们在10Hz的系统采样率下捕获了3个宽切片用于深度估计,另外还捕获了3-4个窄切片及其被动对应。
雷达。对于雷达传感,我们使用77 GHz的专有调频连续波(FMCW)雷达,角度分辨率为1°,距离可达200米。该雷达提供15 Hz的位置速度检测。
激光雷达。在车顶上,我们安装了Velodyne的两台激光扫描仪,即HDL64 S3D和VLP32C。两者都在903nm下工作,并且可以在10Hz下提供双返回(最强和最后)。Velodyne HDL64 S3D提供了64线角度分辨率为0.4°的均匀分布扫描线,Velodyne VLP32C提供了32线非线性分布扫描线。HDL64 S3D和VLP32C扫描仪的范围分别为100米和120米。
FIR摄像机。使用Axis Q1922 FIR相机以30 Hz拍摄热图像。相机分辨率为640×480,像素间距为17µm,噪声等效温差(NETD)<100 mK。
环境传感器。我们使用Airmar WX150气象站测量了环境信息,该气象站提供温度、风速和湿度,并配备了专有的道路摩擦传感器。所有传感器都是时间同步的,并使用专用惯性测量单元(IMU)校正自我运动。系统提供10 Hz的采样率。
3.2 记录
真实世界记录。2019年2月和12月在德国、瑞典、丹麦和芬兰进行了两次试驾,每次试驾两周,在不同的天气和照明条件下行驶10000公里,采集了所有实验数据。以10Hz的帧速率总共收集了140万帧。每100帧被手动标记以平衡场景类型覆盖。生成的注释包含5.5k清晰天气帧、1k浓雾捕获、1k轻雾捕获和4k雪/雨捕获。鉴于大量的捕获工作,这表明在恶劣条件下的训练数据很少。我们通过仅对清晰数据进行训练和对恶劣数据进行测试来解决这一问题。训练和测试区域没有任何地理重叠。我们不是按帧划分,而是基于来自不同位置的独立记录(长度为5-60分钟)来划分数据集。这些记录来自图2所示的18个不同的主要城市和沿线的几个较小城市。
受控条件记录。为了在受控条件下收集图像和距离数据,我们还提供了在雾室中获得的测量结果。有关雾室设置的详细信息,请参见[17,13]。我们以10 Hz的帧速率捕获了35k帧,并在两种不同的照明条件(白天/夜晚)和三种雾密度(气象能见度V为30 m、40 m和50 m)下标记了15k帧的子集。补充材料中给出了详细信息,其中我们还使用[52]中的正向模型与模拟数据集进行了比较。
4. 自适应深度融合
在本节中,我们描述了所提出的自适应深度融合架构,该架构允许在存在未知不对称传感器失真的情况下进行多模态融合。我们在自动驾驶车辆和自动驾驶无人机所需的实时处理约束下设计我们的架构。具体而言,我们提出了一种有效的单发融合架构。
4.1 自适应多模态单发融合
提议的网络架构如图4所示。它由多个单发检测分支组成,每个分支分析一个传感器模态。
数据表示法。相机分支使用传统的三平面RGB输入,而对于激光雷达和雷达分支,我们偏离了最近的鸟瞰图(BeV)投影[36]方案或原始点云表示[65]。BeV投影或点云输入不允许深度早期融合,因为早期层中的特征表示与相机特征固有不同。因此,现有的BeV融合方法只能在匹配区域提案后,在提升空间中融合特征,但不能更早。图4显示了建议的输入数据编码,这有助于深度多模态融合。我们不使用单纯的深度输入编码,而是提供深度、高度和脉冲强度作为激光雷达网络的输入。对于雷达网络,我们假设雷达在与图像平面正交且与水平图像维度平行的2D平面中扫描。因此,我们认为雷达沿垂直图像轴不变,并沿垂直轴复制扫描。使用单应性映射将门控图像转换为RGB相机的图像平面,请参见补充材料。所提出的输入编码允许不同流之间的像素级对应的位置和强度相关融合。我们用零值编码缺失的测量样本。
特征提取。作为每个流中的特征提取堆栈,我们使用修改的VGG[55]主干。与[36,11]类似,我们将通道数量减少一半,并在conv4层切断网络。受[41,39]启发,我们使用conv4-10中的六个特征层作为SSD检测层的输入。特征图的大小减小(我们使用特征图金字塔[(24,78),(24,79),(12,39),(12,39),(6,20),(3,10)]),在不同的尺度上实现了用于检测的特征金字塔。如图4所示,交换了不同特征提取堆栈的激活。为了将融合引向最可靠的信息,我们向每个特征交换块提供传感器熵。我们首先卷积熵,应用sigmoid,乘以来自所有传感器的级联输入特征,最后级联输入熵。熵的折叠和sigmoid的应用产生了区间[0,1]中的乘法矩阵。这将根据可用信息分别缩放每个传感器的连接特征。具有低熵的区域可以被衰减,而熵丰富的区域可以在特征提取中被放大。这样做可以使我们自适应地融合特征提取堆栈本身中的特征,我们将在下一节中深入讨论这一点。

图4. 我们的架构概述,包括四个单发检测器分支,具有激光雷达、RGB相机、门控相机和雷达的深度特征交换和自适应融合。根据第4.1节,所有传感器数据都投影到摄像机坐标系中。为了引导传感器之间的融合,该模型依赖于提供给每个特征交换块(红色)的传感器熵。深度特征交换块(白色)与并行特征提取块交换信息(蓝色)。融合的特征图由SSD块(橙色)分析。
4.2 熵导向融合
为了将深度融合引向冗余和可靠的信息,我们在每个传感器流中引入熵通道,而不是像[58,60]中那样直接推断恶劣天气类型和强度。我们估计局部测量熵,

在所提出的图像空间数据表示中,为具有像素值I∈[0,255]的每个8位二进制化流I计算熵。每个流被分成大小为M×N=16px×16px的块,从而得到w×h=1920px×1024px的熵图。两种不同场景的多模态熵图如图5所示:左侧场景显示了一个场景,该场景包含受控雾室内的车辆、骑车人和行人。被动RGB相机和激光雷达由于雾能见度降低而遭受反向散射和衰减,而门控相机通过门控抑制反向散射。雷达测量值在雾中也不会显著降低。图5中的正确场景显示了在不同环境照明下的静态室外场景。在这种情况下,主动激光雷达和雷达不受环境照明变化的影响。对于门控相机,环境照明消失,只留下主动照明区域,而被动RGB相机随着环境光的减少而退化。
转向过程完全根据清洁天气数据学习,该数据包含白天到夜间条件下的不同照明设置。训练期间没有出现真正的恶劣天气模式。此外,我们以概率0.5随机丢弃传感器流,并将熵设置为恒定的零值。
4.3 损失函数和训练详情
不同特征层中锚框的数量及其大小在训练期间起着重要作用,并在补充材料中给出。总共使用具有softmax的交叉熵损失来训练具有类标签yi和概率pi的每个锚框,

损失被分成正负锚框,匹配阈值为0.5。对于每个正锚框,使用Huber损失H(x)回归边界框坐标x,

负锚的总数限制为5×使用困难的示例挖掘的正面示例的数量[41,53]。所有网络都是以恒定的学习速率和0.0005的L2权重衰减从头开始训练的。

图5. 门控摄像机、RGB摄像机、雷达和激光雷达在不同雾能见度(左)和不同照明(右)下的清晰参考记录的归一化熵。熵是根据图3(左)所示的受控雾室内的动态场景和具有变化自然照明设置的静态场景(右)计算的。根据公式(1)计算了定量数字。注意不同传感器技术的不对称传感器故障。定性结果如下所示,并通过箭头与相应的雾密度/白天联系起来。
5. 评估
在本节中,我们在未见过的实验测试数据上验证了所提出的融合模型。我们将该方法与现有的单传感器输入检测器、融合方法以及域自适应方法进行了比较。由于训练数据采集的天气偏差,我们只使用提议数据集的晴朗天气部分进行训练。我们使用我们的新型多模态天气数据集作为测试集来评估检测性能,有关测试和训练划分的细节,请参阅补充数据。
我们根据真实的恶劣天气数据验证了表2中提出的方法,我们称之为深度熵融合。我们报告了三个不同难度等级(容易、中等、困难)的平均精度(AP),并在不同雾密度、雪扰动和晴朗天气条件下,根据KITTI评估框架[19]对汽车进行评估。我们将所提出的模型与最近最先进的激光雷达相机融合模型进行了比较,包括AVOD-FPN[36]、Frustum PointNets[49],以及所提出方法的变体与替代融合或传感输入。作为基线变体,我们实现了两个融合和四个单传感器检测器。特别是,我们将图像、激光雷达、门控和雷达特征在边界框回归(fusion SSD)之前连接的后期融合和通过在一个特征提取堆栈的早期开始连接所有传感器数据的早期融合(Concat SSD)进行比较。Fusion SSD网络共享与所提出的模型相同的结构,但没有特征交换和自适应融合层。此外,我们将所提出的模型与具有单一传感器输入的相同SSD分支(仅图像SSD、仅门控SSD、仅激光雷达SSD、仅雷达SSD)进行了比较。所有模型都使用相同的超参数和锚进行训练。
在恶劣天气情况下进行评估,所有方法的检测性能都会降低。请注意,随着天气划分之间场景复杂性的变化,评估指标可能会同时增加。例如,当参与道路交通的车辆减少或在结冰条件下车辆之间的距离增加时,阻塞的车辆就会减少。虽然图像和门控数据的性能几乎稳定,但激光雷达数据的性能显著下降,而雷达数据的则有所提高。激光雷达性能的下降可以用强烈的反向散射来描述,见补充材料。由于最多100个测量目标限制了雷达输入的性能,因此报告的改进是由于更简单的场景。

表2. 来自数据集的真实未观测天气影响数据的定量检测AP,该数据集在天气和困难情况下划分,容易/中等/困难跟随[19]。除了域自适应方法之外,所有检测模型都只在没有天气失真的干净数据上进行训练。最佳模型以粗体突出显示。(1需要大量恶劣天气数据进行训练。)
总体而言,在雾天条件下,激光雷达性能的大幅降低影响了仅激光雷达的检测率,AP下降了45.38%。此外,它还对摄像机激光雷达融合模型AVOD、Concat SSD和fusion SSD产生了强烈影响。学习冗余不再有效,这些方法甚至低于仅图像方法。
两个阶段的方法,如Frustum PointNet[49],很快就会失败。然而,与AVOD相比,它们渐进地获得了更高的结果,因为第一阶段学习的统计先验是基于仅图像SSD的,这将其性能限制在图像域先验。AVOD受到天气晴好的几个假设的限制,例如在训练期间对装满激光雷达数据的框进行重要采样,从而达到最低的融合性能。此外,随着雾密度的增加,所提出的自适应融合模型优于所有其他方法。特别是在严重失真的情况下,所提出的自适应融合层在没有它的模型上产生了显著的裕度(深度融合)。总体而言,所提出的方法优于所有基线方法。在浓雾中,与下一个最佳特征融合变体相比,它提高了9.69%。
为了完整性,我们还将所提出的模型与最近的域自适应方法进行了比较。首先,我们将我们的仅图像SSD功能从晴朗天气调整为恶劣天气[61]。其次,我们利用[29]研究了从晴空天气到恶劣天气的风格转换,并从晴空输入生成恶劣天气训练样本。请注意,这些方法与所有其他比较方法相比具有不公平的优势,因为它们看到了从我们的验证集采样的恶劣天气场景。注意,域自适应方法不能直接应用,因为它们需要来自特定域的目标图像。因此,它们也不能为数据有限的罕见边缘情况提供解决方案。此外,[29]没有模拟变形,包括雾或雪,参见补充材料中的实验。我们注意到,[52]之后的合成数据增强或消除恶劣天气影响的图像到图像重建方法[64]既不会影响所提出的多模态深度熵融合的报告边缘。
6. 结论和未来工作
在本文中,我们解决了自动驾驶中的一个关键问题:场景中的多传感器融合,其中注释数据由于自然天气偏差而稀疏且难以获得。为了评估恶劣天气中的多模态融合,我们引入了一个新的恶劣天气数据集,包括相机、激光雷达、雷达、门控NIR和FIR传感器数据。该数据集包含了在北欧行驶超过10000公里的罕见场景,如大雾、大雪和大雨。我们提出了一种实时深度多模态融合网络,它不同于建议级融合,而是由测量熵驱动的自适应融合。未来研究的令人兴奋的方向包括开发端到端模型,以实现故障检测和自适应传感器控制,如激光雷达传感器中的噪声级或功率级控制。
Acknowledgment
The authors would like to acknowledge the funding from the European Union under the H2020 ECSEL Programme as part of the DENSE project, contract number 692449, and thank Jason Taylor for fruitful discussion.
References
[1] C. O. Ancuti, C. Ancuti, R. Timofte, and C. D. Vleeschouwer. O-haze: A dehazing benchmark with real hazy and haze-free outdoor images. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 867–8678, 2018. 2
[2] V. Badrinarayanan, A. Kendall, and R. Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(12):2481–2495, Dec 2017. 2
[3] M. Bijelic, T. Gruber, and W. Ritter. Benchmarking image sensors under adverse weather conditions for autonomous driving. In 2018 IEEE Intelligent Vehicles Symposium (IV), pages 1773–1779, 2018. 5
[4] M. Bojarski, D. Del Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Monfort, U. Muller, J. Zhang, et al. End to end learning for self-driving cars. arXiv preprint arXiv:1604.07316, 2016. 2
[5] G. J. Brostow, J. Shotton, J. Fauqueur, and R. Cipolla. Segmentation and recognition using structure from motion point clouds. In Proceedings of the IEEE European Conference on Computer Vision, pages 44–57. Springer, 2008. 2
[6] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom. nuscenes: A multimodal dataset for autonomous driving. arXiv preprint arXiv:1903.11027, 2019. 1, 3
[7] B. Cai, X. Xu, K. Jia, C. Qing, and D. Tao. DehazeNet: An end-to-end system for single image haze removal. IEEE Transactions on Image Processing, 25(11):5187–5198, 2016. 2
[8] Z. Cai, Q. Fan, R. S. Feris, and N. Vasconcelos. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the IEEE European Conference on Computer Vision, pages 354–370. Springer, 2016. 2
[9] M. Chang, J. Lambert, P. Sangkloy, J. Singh, S. Bak, A. Hartnett, D. Wang, P. Carr, S. Lucey, D. Ramanan, and J. Hays. Argoverse: 3d tracking and forecasting with rich maps. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8740–8749, 2019. 2
[10] J. Chen, C.-H. Tan, J. Hou, L.-P. Chau, and H. Li. Robust video content alignment and compensation for rain removal in a cnn framework. CVPR, 2018. 3
[11] X. Chen, H. Ma, J. Wan, B. Li, and T. Xia. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1907–1915, 2017. 1, 2, 3, 5
[12] H. Cho, Y.-W. Seo, B. V. Kumar, and R. R. Rajkumar. A multi-sensor fusion system for moving object detection and tracking in urban driving environments. In Robotics and Automation (ICRA), 2014 IEEE International Conference on, pages 1836–1843. IEEE, 2014. 2
[13] M. Colomb, J. Dufour, M. Hirech, P. Lacˆote, P. Morange, and J.-J. Boreux. Innovative artificial fog production devicea technical facility for research activities. In Atmospheric Research, 2004. 5
[14] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016. 2
[15] D. Dolgov, S. Thrun, M. Montemerlo, and J. Diebel. Path planning for autonomous vehicles in unknown semi-structured environments. The International Journal of Robotics Research, 29(5):485–501, 2010. 3
[16] P. Dollar, C. Wojek, B. Schiele, and P. Perona. Pedestrian detection: An evaluation of the state of the art. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(4):743–761, 2012. 2
[17] P. Duthon, F. Bernardin, F. Chausse, and M. Colomb. Methodology used to evaluate computer vision algorithms in adverse weather conditions. Transportation Research Procedia, 14:2178–2187, 2016. 5
[18] D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In Advances in neural information processing systems, pages 2366–2374, 2014. 2
[19] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3354–3361, 2012. 1, 2, 3, 7, 8
[20] R. Girshick. Fast r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1440–1448, 2015. 2
[21] C. Godard, O. Mac Aodha, and G. J. Brostow. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 270–279, 2017. 2
[22] Y. Grauer. Active gated imaging in driver assistance system. Advanced Optical Technologies, 3(2):151–160, 2014. 2
[23] T. Gruber, F. Julca-Aguilar, M. Bijelic, and F. Heide. Gated2depth: Real-time dense lidar from gated images. In Proceedings of the IEEE International Conference on Computer Vision, 2019. 2, 4, 5
[24] S. Hasirlioglu, A. Kamann, I. Doric, and T. Brandmeier. Test methodology for rain influence on automotive surround sensors. In IEEE International Conference on Intelligent Transportation Systems, pages 2242–2247. IEEE, 2016. 4
[25] K. He, J. Sun, and X. Tang. Single image haze removal using dark channel prior. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(12):2341–2353, 2011. 3
[26] R. Heinzler, P. Schindler, J. Seekircher, W. Ritter, and W. Stork. Weather influence and classification with automotive lidar sensors. In 2019 IEEE Intelligent Vehicles Symposium (IV), pages 1527–1534, 2019.
[27] A. B. Hillel, R. Lerner, D. Levi, and G. Raz. Recent progress in road and lane detection: a survey. Machine vision and applications, 25(3):727–745, 2014. 2
[28] J. Hoffman, T. Darrell, and K. Saenko. Continuous manifold based adaptation for evolving visual domains. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 867–874, 2014. 3
[29] J. Hoffman, E. Tzeng, T. Park, J.-Y. Zhu, P. Isola, K. Saenko, A. A. Efros, and T. Darrell. Cycada: Cycle-consistent adversarial domain adaptation. In ICML, 2017. 2, 3, 8
[30] P. Hurney, P. Waldron, F. Morgan, E. Jones, and M. Glavin. Review of pedestrian detection techniques in automotive far-infrared video. IET intelligent transport systems, 9(8):824– 832, 2015. 1
[31] S. Inbar and O. David. Laser gated camera imaging system and method, may 2008. 4
[32] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. In CVPR, pages 1125–1134, 2017. 3
[33] M. B. Jensen, M. P. Philipsen, A. Møgelmose, T. B. Moeslund, and M. M. Trivedi. Vision for looking at traffic lights: Issues, survey, and perspectives. IEEE Transactions on Intelligent Transportation Systems, 17(7):1800–1815, 2016. 2
[34] S. Ki, H. Sim, J.-S. Choi, S. Kim, and M. Kim. Fully endto-end learning based conditional boundary equilibrium gan with receptive field sizes enlarged for single ultra-high resolution image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 817–824, 2018. 2
[35] J. Kim, J. Choi, Y. Kim, J. Koh, C. C. Chung, and J. W. Choi. Robust camera lidar sensor fusion via deep gated information fusion network. In IEEE Intelligent Vehicle Symposium, pages 1620–1625. IEEE, 2018. 3
[36] J. Ku, M. Mozifian, J. Lee, A. Harakeh, and S. L. Waslander. Joint 3d proposal generation and object detection from view aggregation. In IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 1–8. IEEE, 2018. 1, 2, 3, 5, 7, 8
[37] O. Kupyn, V. Budzan, M. Mykhailych, D. Mishkin, and J. Matas. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8183–8192, 2018. 2, 3
[38] B. Li, X. Peng, Z. Wang, J. Xu, and D. Feng. Aod-net: Allin-one dehazing network. In International Conference on Computer Vision (ICCV), pages 4780–4788, Oct 2017. 2, 3
[39] T. Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 936–944, July 2017. 5
[40] F. Liu, C. Shen, G. Lin, and I. D. Reid. Learning depth from single monocular images using deep convolutional neural fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(10):2024–2039, 2016. 2
[41] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y.Fu, and A. C. Berg. Ssd: Single shot multibox detector. In Proceedings of the IEEE European Conference on Computer Vision, pages 21–37. Springer, 2016. 1, 2, 5, 7
[42] M. Long, Z. Cao, J. Wang, and M. I. Jordan. Conditional adversarial domain adaptation. In Advances in Neural Information Processing Systems, pages 1640–1650, 2018. 2
[43] W. Luo, B. Yang, and R. Urtasun. Fast and furious: Real time end-to-end 3d detection, tracking and motion forecasting with a single convolutional net. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3569–3577, 2018. 1, 2, 3
[44] O. Mees, A. Eitel, and W. Burgard. Choosing smartly: Adaptive multimodal fusion for object detection in changing environments. In IEEE International Conference on Intelligent Robots and Systems, pages 151–156. IEEE, 2016. 3
[45] Z. Murez, S. Kolouri, D. Kriegman, R. Ramamoorthi, and K. Kim. Image to image translation for domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4500–4509, 2018. 2
[46] U. D. of Commerce / National Oceanic and A. Administration. Fog definition. Federal Meteorological Handbook No. 1: Surface Weather Observations and Reports. U.S. Department of Commerce / National Oceanic and Atmospheric Administration, 2005. 3
[47] D. Park, H. Park, D. K. Han, and H. Ko. Single image dehazing with image entropy and information fidelity. In 2014 IEEE International Conference on Image Processing (ICIP), pages 4037–4041, 2014. 2
[48] C. Premebida, O. Ludwig, and U. Nunes. Lidar and vision-based pedestrian detection system. Journal of Field Robotics, 26(9):696–711, 2009. 3
[49] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 918–927, 2018. 3, 7, 8
[50] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems, pages 91–99, 2015. 3
[51] C. Sakaridis, D. Dai, and L. V. Gool. Guided curriculum model adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pages 7374–7383, 2019. 3
[52] C. Sakaridis, D. Dai, and L. Van Gool. Semantic foggy scene understanding with synthetic data. International Journal of Computer Vision, pages 1–20, 2018. 2, 3, 5, 8
[53] A. Shrivastava, A. Gupta, and R. Girshick. Training regionbased object detectors with online hard example mining. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Jun 2016. 7
[54] H. Sim, S. Ki, J.-S. Choi, S. Seo, S. Kim, and M. Kim. Highresolution image dehazing with respect to training losses and receptive field sizes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 912–919, 2018. 2
[55] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 201. 5
[56] V. A. Sindagi, Y. Zhou, and O. Tuzel. Mvx-net: Multimodal voxelnet for 3d object detection. In 2019 International Conference on Robotics and Automation (ICRA), pages 7276– 7282, 2019. 3
[57] S. Song and J. Xiao. Deep sliding shapes for amodal 3d object detection in rgb-d images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 808–816, 2016. 1
[58] R. Spinneker, C. Koch, S. Park, and J. J. Yoon. Fast fog detection for camera based advanced driver assistance systems. In IEEE International Conference on Intelligent Transportation Systems, pages 1369–1374, Oct 2014. 3, 6
[59] P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V. Patnaik, P. Tsui, J. Guo, Y. Zhou, Y. Chai, B. Caine, V. Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y. Zhang, J. Shlens, Z. Chen, and D. Anguelov. Scalability in perception for autonomous driving: Waymo open dataset, 2019. 1, 2, 3
[60] J.-P. Tarel, N. Hautiere, A. Cord, D. Gruyer, and H. Halmaoui. Improved visibility of road scene images under heterogeneous fog. In Intelligent Vehicles Symposium (IV), 2010 IEEE, pages 478–485. Citeseer, 2010. 3, 6
[61] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7167–7176, 2017. 3, 8
[62] G. J. van Oldenborgh, P. Yiou, and R. Vautard. On the roles of circulation and aerosols in the decline of mist and dense fog in europe over the last 30 years. Atmospheric Chemistry and Physics, 10(10):4597–4609, 2010. 2, 3
[63] T.-H. Vu, H. Jain, M. Bucher, M. Cord, and P. P´erez. Dada: Depth-aware domain adaptation in semantic segmentation. In ICCV, 2019. 3
[64] T.-C. Wang, M.-Y. Liu, J.-Y. Zhu, A. Tao, J. Kautz, and B. Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8798–8807, 2018. 8
[65] D. Xu, D. Anguelov, and A. Jain. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 244–253, 2018. 1, 2, 3, 5
[66] H. Xu, Y. Gao, F. Yu, and T. Darrell. End-to-end learning of driving models from large-scale video datasets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2174–2182, 2017. 2, 3
[67] B. Yang, W. Luo, and R. Urtasun. Pixor: Real-time 3d object detection from point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7652–7660, 2018. 1
[68] M.-h. Yang, V. M. Patel, J.-s. Choi, S. Kim, B. Chanda, P. Wang, Y. Chen, A. Alvarez-gila, A. Galdran, J. Vazquezcorral, M. Bertalmo, H. S. Demir, and J. Chen. NTIRE 2018 Challenge on Image Dehazing : Methods and Results. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 1–12, 2018. 2
[69] F. Yu, W. Xian, Y. Chen, F. Liu, M. Liao, V. Madhavan, and T. Darrell. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv preprint arXiv:1805.04687, 2018. 3
[70] Y. Zhang, P. David, and B. Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. Proceedings of the IEEE International Conference on Computer Vision, pages 2039–2049, 2017. 3
[71] Y. Zhang, Y. Tian, Y. Kong, B. Zhong, and Y. Fu. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2472–2481, 2018. 2
[72] Y. Zhou and O. Tuzel. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4490–4499, 2018. 1
[73] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired imageto-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2223–2232, 2017. 3
[74] J. Ziegler, P. Bender, M. Schreiber, H. Lategahn, T. Strauss, C. Stiller, T. Dang, U. Franke, N. Appenrodt, C. G. Keller, E. Kaus, R. G. Herrtwich, C. Rabe, D. Pfeiffer, F. Lindner, F. Stein, F. Erbs, M. Enzweiler, C. Kn¨oppel, J. Hipp, M. Haueis, M. Trepte, C. Brenk, A. Tamke, M. Ghanaat, M. Braun, A. Joos, H. Fritz, H. Mock, M. Hein, and E. Zeeb. Making bertha drive—an autonomous journey on a historic route. IEEE Intelligent Transportation Systems Magazine, 6(2):8–20, 2014. 1
补充材料
本补充文件提供了关于提议数据集、附加方法细节以及附加结果和比较的附加信息。
1. 附加的数据集详细信息
主文件第3节描述了提议数据集。在本节中,我们将介绍附加的详细信息,包括预选和多模式注释过程,以及受控天气捕获设置。
我们在图8、9、10和11中展示了数据集的多样性。
1.1 数据预选流程
在注释之前,我们预先选择图像,因为其中许多图像由于低场景变化、传感器故障、雨刷器或没有目标而不相关,见图4。低场景变化的帧通常包含在红绿灯处等待或在长道路上跟随同一辆车时的场景。传感器故障是由技术问题或传感器被雪或灰尘覆盖引起的。
具体而言,从数据集中均匀地采样0.1 Hz帧速率的图像,总共提供17799幅图像。这些图像标注了场景天气和语义内容(丢弃/可有可无/适当/非常有趣)。此外,如果在采样帧附近发现有趣的内容,我们使用插值标记图像。44.66%的所选图像被注释为丢弃或可有可无。为了增加具有有趣语义内容的序列的数量,我们还以1Hz的帧速率导出了包含插入注释的帧的序列,从而获得了额外的4561个样本。在这个过程之后,由于得到的子集偏向于良好的天气数据,我们在恶劣天气中以1Hz的帧速率额外导出了至少一个非常有趣的标签的序列,并获得了额外的6444帧。总共有28804帧使用场景天气和语义内容分类进行了注释。从这些帧中,我们过滤掉了天气注释在录制过程中快速变化的帧——我们认为这些注释有噪音或不明确。最后,我们选择了最有趣的场景,至少用适当的场景内容进行了注释,从而生成了12000个带注释的帧用于边界框标记。
1.2 数据注释流程
目标注释过程如图1所示。该过程从激光雷达和雷达点云中的3D边界框注释开始。我们标注了距离达80米的3D框。由于点云的稀疏性,生成的3D边界框在RGB相机框架中可视化,用于调整位置和尺寸。我们使用RGB图像可视化为激光雷达/雷达标注过程中丢失的目标添加2D边界框。此外,对于每个3D框,通过将3D框作为2D框投影到RGB相机框架中并将其拧紧以适合相机框架中的2D目标形状,来添加额外的2D框。如果用于注释三维长方体的点太少,则在两个相机流中使用二维长方体对可见目标进行注释,目标高度可达30像素。最后,注释被传输到门控框架中。
我们根据以下类型/类别标记目标:行人、卡车、汽车、自行车和DontCare。总数据分布见图3。对于每个绘制的目标,我们还包括标记,这些标记指示每个传感器流中的遮挡级别(无遮挡、>10%、>40%和>80%遮挡)和目标可见性。此外,我们还包括以下场景标签:图像白天(白天、夜晚、黎明)、照明(低动态范围、高动态范围、最佳计算机视觉天气、整体黑暗)、天气(晴、雨、轻雾、浓雾、雪)、可导出的路径条件(干燥、潮湿、泥泞、全雪覆盖)和场景设置(市中心、郊区、高速公路)。

图1. 该图说明了数据注释过程,该过程在使用3D边界框的激光雷达和雷达组合框架中开始。通过可视化相机流中的3D框,对其进行校正,以适应每个传感器流中的目标尺寸和位置。此外,在RGB摄影机和门控摄影机中标注二维边界框。对于RGB数据,人类注释器将投影的3D框收紧为2D目标外观。如果传感器流中有任何可见的缺失目标,则会添加额外的2D框。

图2. 总的和不同天气条件下的目标分布。注意目标分布是如何从总体变化到不同的天气条件的。
1.3 受控天气数据集
我们在气象室中受控的恶劣天气条件下记录了典型的街道场景。我们设计了六种动态场景,如图6所示,即横穿行人、人行道上的行人、街道上的骑车人、横穿行人和街道上的一名骑车人、迎面而来的汽车、横穿行人、街道和迎面而来汽车。所有这些动态场景都是在八种不同的照明条件和三种不同的雾密度下进行的。照明条件可以通过打开和关闭室内的温室部分、改变相互作用的汽车的方向(迎面驶来/驶离)以及打开和关闭前照灯和街灯来改变。除了在大约30米、40米和50米的能见度下的三种不同雾度外,还记录了不同雨强度下的一些场景。然而,由于可用水量有限,这些情况是有限的。对于注释过程,我们在所有场景和照明条件下随机选择了1500个。由于激光雷达在雾和雨中的糟糕性能,3D边界框的标注具有挑战性,我们仅在rgb和门控相机中标注了2D边界框。图7显示了受控天气数据集的图像示例。
2. 附加定性检测结果
我们在图13和图16中显示了额外的定性检测结果。特别是,我们展示了训练过程中看不到的各种变形,包括由于降雪、喷雾和不正确的曝光控制造成的变形。在所有示例中,所提出的方法都能鲁棒地处理非对称多模态失真,验证了该方法能很好地推广到具有挑战性的未知条件。
3. 附加训练详情
3.1 锚框
为了最佳地表示训练数据分布,我们使用了K均值聚类算法,并采用了[14]中的联合距离度量。训练边界框根据其宽度和高度进行聚集。
总共选择了21个锚。这些锚框最终根据每个特征图的分辨率进行调整,早期特征图的锚框比后期特征图的小。

图3. 显示了子采样数据集的标记分布。为基础设施、环境、照明和昼夜条件提供了附加标签。

表1. 从全融合模型中丢弃单个传感器的消融研究。
3.2 图像同态
为了将门控图像映射到其对应的RGB图像,我们利用两个传感器之间的平面单应性。平面单应性通过图17所示的静态场景进行校准。对于每个图像,人类注释器标记了170个对应点。使用RANSAC[5]优化对映射进行优化。
3.3 单个传感器的贡献
为了评估每个传感器的贡献,我们从全融合模型中删除每个传感器。结果见表1。请注意,评估是基于全RGB相机打开角度。这里只有RGB摄像头覆盖了整个视图,而门控摄像头和雷达提供了更小的和激光雷达更大的打开角度。
3.4 激光雷达输入表示
为了测试可能的最佳激光雷达输入表示,我们测试了不同的激光雷达输入配置。默认情况下,我们将激光雷达点投影到相机坐标系中,并使用距离、高度和强度作为输入。该表示有助于我们模型中的相机激光雷达融合。输入是以零为中心的,并在[−127.5,127.5]之间进行缩放。除了此建议的表示之外,我们还测试了移位的[0,255]输入表示(移位)和[0,1]之间的归一化(单位缩放)。在表2中,我们列出了定量结果,这些结果表明,所有标准化方法都表现良好。

图4. 注释前已预先选择记录的数据。因此,整个数据集以0.1 Hz的频率导出。(a) 为了确保明确的天气条件,我们忽略了天气注释快速变化的样本。(b) 由于场景变化小、传感器故障或场景中没有目标,我们忽略了所有选定帧的44.66%。丢弃原因的分布如(c)所示。用“插值”注释的帧显示了较低的场景差异,但以下帧可能很有趣。因此,已经以1Hz的较高帧速率对这些序列进行了上采样,并且已经选择了感兴趣的帧。

表2. 不同激光雷达数据归一化方法的消融研究。
3.5 运行时评估
我们未经优化的Tensor RT实现在我们的原型推理平台上以22.6 Hz运行,使用四个Nvidia V100 GPU,每个GPU处理一个传感器功能堆栈。这种吞吐量性能与最近的实时相机激光雷达检测方法相当,包括以12 Hz运行的AVOD、10.75 Hz的PIXOR和0.8 Hz的PointFusion。请注意,我们的网络是以32位浮点精度实现的,我们将整数量化(通常用于生产部署)留给未来工作。
4. 附加域适配结果
为了完整性,我们验证了所提出的针对域自适应的方法。具体而言,我们将其与特征自适应和数据集自适应进行比较。对于特征自适应,晴朗天气模型的权重适应恶劣的天气条件。对于数据集自适应,我们学习从晴空天气条件到恶劣天气场景的图像到图像映射,以便晴空天气训练数据集可以转换为具有相同标签的恶劣天气数据集。这可以减少恶劣天气场景中数据收集活动的数量,因为恶劣天气风格可以转移到有趣的晴朗天气场景中。
然而,领域自适应不模拟可能独立于样式出现的失真。例如,雾可能出现在夏季或冬季,这可能会改变场景语义,并且场景目标可能会由于雾而被完全移除。此外,这些方法需要大量(未标注的)图像数据集——这不是一个小问题,因为恶劣天气很少发生,而且变化很快。因此,理论上,领域自适应目前并不能提供克服现有驱动数据集偏差的解决方案。我们通过额外的实验验证了这一点。请注意,这些实验是不公平的,因为所比较的适用于域的方法已经看到了来自验证集的恶劣天气数据。

图5. 拟议数据集中的图像失真示例。我们将失真类型注释为每个子图形的标题。

图6. 在受控天气条件下记录的六种不同场景的图解。

图7. 两种场景和两种不同照明设置(a、b)下的雾室图像示例。左列显示了移动行人和骑车人的动态场景。中间和右侧的列显示了相同的场景,在不同的环境光下,研究车前面有一辆移动的汽车。
4.1 附加特征适配结果
将晴好天气的特征与恶劣天气条件相适应,有助于减少在恶劣天气条件下训练模型所需的数据量。即使它需要未配对的恶劣天气和清晰样本,它也不需要带注释的2D框。在我们的案例中,我们使用纯图像SSD作为晴朗天气条件下的预训练模型,并在VGG主干的block4之后剪切特征提取部分。该特征提取器适合于通过训练ADDA[16](批量大小为5,学习率为0.0001)和具有1024个隐藏单元、2048个隐藏单元和对抗性鉴别器输出的三个完全连接层的对抗网络,从采样的恶劣天气条件中获取目标图像。由于图像的大小,我们无法在GPU中容纳每批超过五个图像。即使对特征提取器进行了调整,结果也会减少,如主要手稿的表2所示。我们假设性能下降是由不同的恶劣天气现象引起的,从照明变化到不同的环境条件,即道路上的积雪覆盖以及空气中可见的扰动模式(水滴或雪花)。然而,道路交通参与者数量的变化也改变了激活模式。对于图像到图像的映射也可以观察到这一点。
4.2 附加数据集适配结果
图像到图像映射学习风格不同(例如夏季/冬季或白天/夜晚)但除了语义相同的场景之间的映射。我们使用最近的CyCADA[9]方法来学习从清晰的大规模KITTI数据到我们的实验场景的映射。这两个数据集都包含大量样本。生成的模型在清晰的场景之间很好地传输数据,如图18和图19的前两行所示。然而,从清晰的KITTI数据到我们的完整实验训练数据集(包括好天气和坏天气)的模型训练失败,如图18和图19的最后四行所示。定性地说,网络只改变图像样式,例如将黑色道路转换为白色道路,或将所有绿色树木绘制为灰色/黑色。然而,尤其是为了真实地创建雾和雨,必须更改场景语义。这导致在生成的经域变换的恶劣天气图像中产生大量伪影。
为了减少区域差异,我们将我们提出的数据集中的清晰图像映射到恶劣的天气场景。在图20中,我们可以观察到网络没有学会映射困难的扰动。该网络只应用从晴朗天气到冬季场景的风格转换。建议的简化结果可能是一个缺点,因为GAN鉴别器的鉴别力可能太弱,无法完成这项任务,只能学习“是否有积雪覆盖的道路?”等简单特征。此外,可以观察到,不同的照明条件没有正确地转换到恶劣的天气场景。
4.3 附加语义适应结果
为了测试语义适应能力,我们使用DADA[17]将Cityscapes[2]中的晴空RGB图像适应到我们的恶劣天气RGB图像。请注意,改编是成功的,但这项任务不仅仅意味着视角和纹理的改变。在恶劣天气下,语义可能会发生根本性变化,例如积雪覆盖的道路导致道路和人行道之间的边界消失,或恶劣天气记录中不同程度的退化信息,例如夜间驾驶时的完全遮光区域,或迎面驶来的汽车使车辆轮廓变黑,雾天驾驶时天空信息与物体混合。代表性示例如图21所示。
5. 附加模拟结果
在本节中,我们提供了额外的结果,将模拟数据添加到清晰的训练数据中,作为应对罕见恶劣天气条件的替代方法。由于所提出的数据集中雾的测量很少,我们选择对雾引起的测量失真进行建模,这是现有融合技术下降最多的天气条件。我们通过Sakaridis等人最近提出的数据增强技术来解决这些雾状条件。[15]。注意,所提出的正向模型也有助于解释观察到的失真。
5.1 雾中的强度成像
在雾状条件下,光在落入图像传感器之前被悬浮的水滴散射。这种散射现象有两个主要影响。首先,主光线在落入传感器之前被衰减,第二,存在散射光的信号基底。这两种效果都会降低对比度,观察到的雾状图像可以通过[15]建模
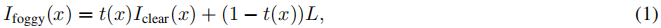
其中Iclear是潜在的清晰图像,取决于深度的透射率t,即全局环境分量L。透射系数为t(x)=exp(-βd(x)),其中β是雾密度(或衰减)系数,d(x)是像素处的场景深度。指数衰减模型与受控雾室测量结果一致,我们已在图25中进行了验证。为此,我们捕获了与图23中相同的目标在不同距离处的测量结果。我们对目标上的强度进行了平均,这些强度通过人类注释器进行了标记,相应的深度已经用手精确测量。每个曲线对应于不同的反射目标,其值为5%、50%和90%。有趣的是,在8米处可以观察到峰值。这个峰值可以通过场景照明来解释。周围的所有照明源都已关闭。场景仅通过车辆的远光灯照明。从9米开始,目标完全位于前照灯照明锥内。给定校准的强度曲线,可以拟合距离d>9m的方程1中的模型,即,
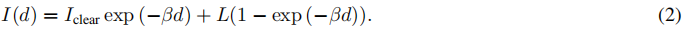
I(d)表示距离d处的平均强度,β对应于测量的雾密度,Iclear表示目标基线反射率,L表示空气灯。
5.2 雾中的脉冲激光雷达
扫描激光雷达系统通过聚焦的高峰值功率脉冲主动照亮场景,从而简化测量模型

其中Lclear(x)是针对给定重复率测量的发射激光束强度,Lfoggy(x)为接收激光强度。注意,我们假设光束发散不受雾的影响。在该模型中,只要接收到的激光强度大于有效噪声下限,则始终记录返回的脉冲回波。然而,来自雾的严重后向散射可能导致来自散射雾体积内的点的直接后向散射,这通过公式(1)中的透射率t(x)来量化。现代扫描激光雷达系统实现自适应激光增益g,以增加给定噪声基底的信号,另见[7],产生的最大距离为

其中n是可检测的噪声基底。可检测距离随着从等式(3)中接收到的激光强度的倒数和增益的和而对数地减小。因此,在雾中,激光雷达测量不仅会受到峰值强度损失的影响,还会受到后向散射的影响,这会导致雾体积内的峰值偏移,因此目标场景点的所有信息都会丢失。主要论文中的图3显示了在浓雾中的相机激光雷达测量。我们使用算法1模拟被雾扭曲的激光雷达测量。该正向模型基于等式(3)、等式(4)以及验证所选超参数的附加雾室测量。注意,雾中的光束发散被忽略了,我们假设恒定的附加增益g和噪声基底n准确地描述了激光雷达深度测量过程。在此,我们还假设检测到的物体的强度按照方程(3)中的衰减模型呈指数衰减。
我们校准激光扫描仪的增益和噪声基底,以在不同雾密度β下实现真实的雾干扰。基于我们的定量雾室测量、定性真实世界测量以及KITTI数据集[6]中使用的Velodyne HDL64 S2激光雷达的最大视距,我们将Velodyne S2的增益和噪声下限校准为g=0.35和n=0.05,Velodyne HDLS3D的增益和噪声下限校准为g=0.45和n=0.04。最大测量视距如图23和图24所示。我们在两种不同的雾类型([4],1]中定义的平流雾和辐射雾)中评估了我们的模型。最大视距是目标上所有点丢失的距离。使用反射率为90%的校准扩散Zenith Polymer目标估计该距离,并将目标从测试车辆的位置移动到最远的距离,直到它们变得不可见。
除了对入射强度进行建模外,我们还对背散射点的距离失真进行建模,以匹配典型的恶劣天气表现。为了匹配在我们的原型系统中观察到的反向散射点的距离,我们假设如果物体距离大于我们校准的给定雾度可达到的最大距离,则点被雾反向散射。然后,如果雾中的强度是发射强度的一半,则该点以衰减概率plost=exp(-β·dmax)丢失,并被雾反向散射。因此,后向散射点位于距离dnew=−ln(0.5)/β处。此外,我们使用概率prandom和随机阈值=0.1对随机失真进行建模。
为了实现由雾的不均匀性引起的典型点云“摇摆”,这也可以在通过废气引起的低环境光下观察到[8],我们使用算法2中提出的启发式模型来模拟这种行为。具体来说,我们沿着方位角和高度向基础雾密度β添加一组正弦曲线。频率在方位方向[0,2]和高度[0,5]的间隔内随机选择。随着时间的推移,所有功能都会更新,从而由于不均匀雾而产生特征点云摆动效果。

5.3 雾中的门控成像
我们根据仅应用于所考虑的窄选通范围的强度成像模型对选通强度成像进行建模。由于大多数背向散射通过第一个门消除,与传统强度成像相比,透射函数β降低局部对比度的程度显著降低。
5.4 雾中的雷达测量
我们将雷达建模为不受雾状条件影响。
5.5 附加模拟增强检测结果
在这里,我们将额外的合成雾图像添加到训练语料库中。具体来说,我们为清晰的天气数据提取密集的立体深度,并用合成雾图像增强现有数据集。我们使用一个清晰的数据预处理模型,对10个epochs进行微调,并在离散步0.0、0.005、0.1、0.02、0.04、0.06、0.08中对雾密度进行均匀采样。对于仅图像模型,我们可以在表3中观察到轻微的改进。对于仅使用激光雷达的模型,我们只能观察到浓雾条件略有改善,而其他结果则有所下降。这种行为是由于激光雷达点云的稀疏性,特别是由于在增强过程中丢失了许多点。因此,网络了解到目标也可以存在于没有点的区域中,这导致误报数量增加,性能下降。此外,激光雷达模型仅适用于能见度高达50米的浓雾条件,而轻雾跨度高达1000米。将联合增强方法应用于我们的深度熵融合模型可在浓雾条件下获得更高的结果,而其他类别则有所下降。我们将这种行为归因于网络在训练期间进行的不平衡传感器流权衡。如果网络通过广泛的增强了解到激光雷达数据是不可靠的,它将转向其他传感器,以牺牲激光雷达数据表现良好的其他天气类型的性能。我们还通过添加恶劣天气样本观察到了这种行为。

表3. 添加到训练数据集(AUG)中的附加合成失真数据的影响,通过从干净的捕获数据中模拟雾状观测产生。对来自数据集的真实未见过天气影响数据进行定量检测AP,该数据集在天气和困难的情况下划分,容易/中等/困难跟随[6]。增强模型使用了主论文表5中明确的预训练模型。在从β=0.0 1m\frac{1}{m}m1到β=0.08 1m\frac{1}{m}m1维度的不同雾密度范围内,在增强数据采样的基础上,对模型进行了10个epochs的微调。

表4. 作为预处理步骤的附加图像重建对来自数据集的真实未见过天气影响数据的影响,这些数据集在天气和困难情况下划分,容易/中等/困难跟随[6]。所提出的模型仅基于干净的数据进行训练,没有天气失真。最佳模型以粗体突出显示。在这里,我们将我们的深度熵融合网络与单图像和具有图像预处理步骤的去除雾霾的单图像进行比较。
6. 附加的仅图像检测结果
作为进一步的基线,我们评估了现有的雾去除方法,并提出了用于在物体检测之前去除雾的流行图像到图像转换技术的变体。具体来说,我们采用了最近的Pix2PixHD[18]方法,这是一种生成对抗性网络,在保持场景语义的同时,在域之间转换图像。我们使用颜色和亮度抖动数据增强(Pix2PixHD CJ)和AODNet[11]中提出的K矩阵估计(Pix2Pix 2HD AOD)来扩展该模型。我们使用上一节中的模拟雾数据集训练了这些模型,该数据集提供了相应的图像对。图26表明,所提出的增强方案具有较少的伪影,并实现了相对稳定的雾去除和对比度增强。
特别是,我们建议在训练期间添加颜色抖动,以提高对测量数据的鲁棒性。我们使用PyTorch[12]变换和ColorJitter实现,并使用以下参数:亮度0.125、饱和度0.5、色调0.2和对比度0.5。未受干扰的目标图像保持原样。因此,在训练期间,网络还学习在颜色受到干扰时恢复颜色,这对于数据增强步骤是有益的。
真实数据的定性结果如图26所示。请注意,具有此修改的普通AODNet[11]和Pix2PixHD(我们称之为Pix2PixHDAOD)并没有推广到真实数据图26。
尽管我们在这项工作中评估了图像增强方法,但请注意,该信号增强阶段需要包含大量清晰和受干扰图像块的适当训练数据集。这些可以使用前面描述的模拟技术有效地创建,而不需要用于训练的真实恶劣天气数据。但这也将性能限制在可以模拟的干扰类型上。因此,图像增强方法仅略微改善了表4中真实数据的检测结果,因为在真实世界数据集中,雾通常与降雪或挡风玻璃脏污等其他干扰一起出现,见图27。由于我们的仅图像除雾模型仅在合成数据上训练,因此它不能推广到这些情况。目前,据我们所知,目前还没有合适的模拟框架来忠实地对这些失真进行建模,从而使生成的模型推广到野外捕获。
References
[1] M. Colomb, J. Dufour, M. Hirech, P. Lacˆote, P. Morange, and J.-J. Boreux. Innovative artificial fog production device-a technical facility for research activities. In Atmospheric Research, 2004. 9
[2] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016. 8
[3] A. Dudhane and S. Murala. C2msnet: A novel approach for single image haze removal. Jan 2018. 30
[4] P. Duthon, F. Bernardin, F. Chausse, and M. Colomb. Methodology used to evaluate computer vision algorithms in adverse weather conditions. Transportation Research Procedia, 14:2178–2187, 2016. 9
[5] M. A. Fischler and R. C. Bolles. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM, 24:381–395, 1981. 4
[6] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3354–3361, 2012. 9, 11, 12
[7] D. Hall. High definition lidar system, 2007. 9
[8] S. Hasirlioglu, A. Riener, W. Ruber, and P. Wintersberger. Effects of exhaust gases on laser scanner data quality at low ambient temperatures. In 2017 IEEE Intelligent Vehicles Symposium (IV), pages 1708–1713, June 2017. 9
[9] J. Hoffman, E. Tzeng, T. Park, J.-Y. Zhu, P. Isola, K. Saenko, A. A. Efros, and T. Darrell. Cycada: Cycle-consistent adversarial domain adaptation. In ICML, 2017. 8, 23, 24, 25
[10] J. Ku, M. Mozifian, J. Lee, A. Harakeh, and S. L. Waslander. Joint 3d proposal generation and object detection from view aggregation. In IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 1–8. IEEE, 2018. 19, 20
[11] B. Li, X. Peng, Z. Wang, J. Xu, and D. Feng. Aod-net: All-in-one dehazing network. In International Conference on Computer Vision (ICCV), pages 4780–4788, Oct 2017. 12, 30
[12] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer. Automatic differentiation in pytorch. In Advances in Neural Information Processing Systems, 2017. 12
[13] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 918–927, 2018. 19, 20
[14] J. Redmon and A. Farhadi. YOLO9000: better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6517–6525, 2017. 3
[15] C. Sakaridis, D. Dai, and L. Van Gool. Semantic foggy scene understanding with synthetic data. International Journal of Computer Vision, pages 1–20, 2018. 8, 11
[16] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7167–7176, 2017. 8
[17] T.-H. Vu, H. Jain, M. Bucher, M. Cord, and P. P´erez. Dada: Depth-aware domain adaptation in semantic segmentation. In ICCV, 2019. 8, 26
[18] T.-C. Wang, M.-Y. Liu, J.-Y. Zhu, A. Tao, J. Kautz, and B. Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8798–8807, 2018. 12, 30

图8. 来自恶劣天气数据集的随机采样RGB图像,以说明场景、照明和天气条件的多样性。图像从1920×1024裁剪到1248×384。

图9. 来自恶劣天气数据集的随机采样RGB图像,以说明场景、照明和天气条件的多样性。图像从1920×1024裁剪到1248×384。

图10. 来自恶劣天气数据集的随机采样RGB图像,以说明场景、照明和天气条件的多样性。图像从1920×1024裁剪到1248×384。

图11. 来自恶劣天气数据集的随机采样RGB图像,以说明场景、照明和天气条件的多样性。图像从1920×1024裁剪到1248×384。

图12. 训练期间未发现的野外测量失真的其他定性检测结果。左列显示城市场景中浓雾中的干扰,右列显示夜间条件下的检测。

图13. 训练期间未发现的野外测量失真的其他定性检测结果。左右两列显示了郊区道路上不同照明设置下浓雾中的干扰。

图14. 训练期间未发现的野外测量失真的其他定性检测结果。左右两列显示了一条郊区道路,具有亚北极气候,有(左)雾和无(右)雾。

图15. 训练期间未发现的野外测量失真的其他定性检测结果。左栏显示了降雪期间的城市场景,右栏显示了雾中高速公路的检测性能。

图16. 训练期间未发现的野外测量失真的其他定性检测结果。左列显示喷雾和不正确的自动曝光引起的干扰,右列显示雾和夜间的检测。

图17. 用于将门控图像扭曲为RGB图像帧的图像单应性。请注意,rgb图像被裁剪到与门控相机相同的视野。

图18. 使用CyCADA进行域自适应的示例[9]。根据我们的实验数据调整KITTI(左),可以适应冬天下雪的场景,但不能正确模拟雾变形(中)。为完整起见,(右)显示了反向转移。反向传输无法恢复足够的信息,无法正确模拟清晰的场景。

图19. 从KITTI到我们提出的数据集的域适应示例。前两行显示了使用CyCADA[9]从清晰的KITTI到清晰的实验数据的映射,其中仅包含少量伪影。人行道上的雪和从绿色树木到没有叶子的灰色树木的转移是正确的。相比之下,最后四行显示了使用相同方法(失败)从清晰的KITTI到不利天气数据的结果。第三行显示随机放置在场景中的红色发光背光。第四行显示道路上的随机小品标记。第六行显示了错误解读的阴影,完全遮蔽了场景。

图20. 从晴朗的冬季捕获到不利天气场景的域适应示例。前两行显示了使用CyCADA[9]进行风格转换时从清晰图像到清晰冬季拍摄的映射,其中仅包含少量伪影,但注意照明设置未正确更改。最后两行显示了雾/雪捕获的映射,这根本不会改变图像,因为清晰输入图像的外观已经像冬天一样,但没有任何不利的天气干扰。

图21. 在映射到我们不利天气场景的清晰城市景观上训练的语义分割模型的域适应示例。第一行显示了使用DADA[17]从清晰的Cityscapes图像到清晰的冬季图像的转换,其中仅包含一些伪影。第二行显示了对下雪冬季捕获的错误映射。这里的人行道/道路被雪和天空覆盖是不正确的。最后一行显示了对浓雾和夜间场景的适应。图像信息已完全退化,自适应失败。

图22. 雾点云在雾中扰动的合成示例(β=0.04),缺少物体。有效的反向散射物体标记为蓝色,雾的反向散射标记为红色。

图23. 这里,与虚线中的模型预测相比,Velodyne HDL64 S2激光雷达传感器在不同雾密度、雾类型和反射率为90%的反射目标的受控雾室内平流雾中的最大视距。

图24. 与虚线中的模型预测相比,Velodyne HDL64 S3D激光雷达传感器在不同雾密度、雾类型和反射率为90%的反射目标的受控雾室内的平流雾中的最大视距。

图25. 受控环境中测量强度I的拟合模型。用三个校准的漫反射目标测量了强度,值分别为5%、50%和90%。现场记录的能见度V≈50−60 m,β≈0.05−0.06 m−1。公式2中的强度模型被拟合到测量中。距离小于8 m的影响是由于光源的有限视野。

图26. 额外的图像到图像重建结果(从上到下):实际恶劣天气中测量的输入图像、AODNet[11]、DehazeNet[3]、Pix2PixHD[18]、Pix2Pix HD AOD和Pix2PixHD CJ。

图27. 图像重建方法在不可见失真上的失败案例。所学习的失真消除模型仅在合成雾场景中训练,因此具有有限的泛化能力,因为雪和雾可能会组合出现不同的干扰类型。