

数据集中的变量之间可能存在复杂和未知的关系。 重要的是,要找出与量化数据集的变量相关联的程度。 这些知识有助于更好地准备数据以满足线性回归等机器学习算法的期望,其性能随着这些关联的出现而下降。
在本教程中,您将了解相关性是变量之间关系的统计概览,以及如何计算不同类型的变量和关系。
学完本教程后,您将发现:
一种通过计算协方差矩阵来总结两个或多个变量之间线性关系的方法。
一种通过计算人员相关系数来总结两个变量之间线性关系的方法。
一种通过计算Spearman相关系数来总结两个变量之间的单调关系(monotonic relationship )的方法。
教学大纲
教程分为以下五个部分。
关联是什么
测试数据集
协方差
皮尔逊相关
Spearman相关
关联是什么
数据集内的变量之间有很多相关的理由。
例如:
一个变量可能决定或决定另一个变量的值。
一个变量容易和另一个变量相关联。
两个变量可能依赖于第三个未知变量。
这有助于数据分析和建模,更好地理解变量之间的关系。 两个变量的关系在统计学中称为“相关”。 相关性为正的可能性意味着两个变量都向同一方向移动,而相关性为负的可能性意味着一个变量的值增加,另一个变量的值就减少。 相关性可能为零。 也就是说,这些变量不相关。
的正相关:两个变量向同一方向变化
零相关性:与变量之间的变化无相关性
负相关:变量向相反方向变化
如果两个以上的变量密切相关,也就是多重共线性,一些算法的性能会下降。 例如线性回归应该去除其中有噪声的相关变量以提高模型的技能。 您可能也对输入变量和输出变量之间的关联感兴趣。 因为它们可以用于判断哪些变量在开发模型的输入中具有关联性。
关系的结构可能是线性的,也可能是已知的,例如,您不知道两个变量之间是否存在关系以及可能采用的结构。 根据已知的关系和变量的分布状况,可以计算出不同的相关得分。
在本教程中,您将研究与高斯分布呈线性关系的变量的分数。 另一个不假设分布,报告所有单调的(增加或减少的)关系。
测试数据集
在讨论相关方法之前,让我们定义一个数据集来测试这些方法。 我们生成了1,000个对变量样本,它们之间有很强的正相关。 第一个变量是从平均数100、标准偏差20的高斯分布中提取的随机数。 第二个是在第一个变量的值上加上平均值为50、标准偏差为10的高斯噪声。
randn ) )函数生成随机的高斯值(高斯分布的平均值为0,标准偏差为1 ),用我们自己的标准偏差乘以结果,再加上平均值,将值转换为期望的范围。 使用伪随机数生成器,以便每次执行代码时都获得相同的数值样本。
执行此示例时,将首先打印每个变量的平均值和标准偏差。
绘制两个变量的散点图。 因为我们自己做了数据集,所以我知道这两个变量之间有关系。 如果观察散点图,就会发现明显的增加趋势。

测试相关数据集的散布图
在计算相关得分之前,首先必须考虑重要的统计方法——协方差。
协方差
变量之间可能存在线性关系。 这种关系在两个数据样本中增加并一致。 这种关系在两个变量之间称为协方差。 这是根据各样本值之间平均值的乘积计算的。 这些值分别减去平均值。
计算样本协方差:

如果在计算中使用平均值,则可以发现每个数据样本必须符合高斯分布或类高斯分布。 可以通过两个变量是否一起增加(正)或一起减少)来说明协方差。 很难说明协方差的大小。 协方差值为0时,两个变量都是完全独立的。
cov )可以使用NumPy函数计算两个或多个变量之间的协方差矩阵。

的主对角线包括每个变量及其自身的协方差。 矩阵中的其他值表示两个变量之间的协方差。 在这种情况下,其余两个值是相同的,因为它们只计算两个变量的协方差。
我们可以计算测试题中两个变量的协方差矩阵。
以下是一个完整的例子。
fff3d8.png?from=pc”>
协方差和协方差矩阵在统计学和多元分析中应用广泛,主要用于描述两个或多个变量之间的关系。运行这个示例,计算并打印协方差矩阵。
因为每个变量是从高斯分布抽取,并具有线性相关,数据集是由这些变量人为建立的,所以协方差对于描述关系来说是很合适的方法。这两个变量之间的协方差是389.75。我们可以看到它是正向的,即正相关。
单独使用协方差这一统计工具的问题是,解释结果并不容易。所以下面我们来介绍Pearson相关系数。
Pearson相关
Pearson相关系数可用来总结两个数据样本之间线性关系的强度。计算Pearson相关系数是用两个变量的协方差除以每个数据样本标准差的乘积。这是两个变量之间协方差的标准化,从中可以得出一个可解释的分数。
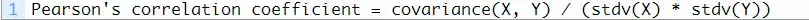
在计算中使用平均值和标准差表明,两个数据样本需要符合高斯或类高斯分布。计算的结果,即相关系数可以被解释,并用于理解其间关系。
该系数返回的值在-1到1之间,表示相关的范围,即从完全负相关到完全正相关。0表示无相关。这个值必须被解释,通常低于-0.5或高于0.5的值表示显著的相关,其他范围的值则表示相关不显著。
pearsonr() SciPy函数可以计算两个相同长度的数据样本的Pearson相关系数。我们可以计算出测试问题中两个变量间的相关。
下面列出了完整的示例。

运行这个示例,计算并打印出Pearson相关系数。
我们可以看到这两个变量存在正相关关系,相关性为0.8。这意味着高相关,因为高于0.5且接近1.0。

可以用Pearson相关系数来评估两个以上变量间的关系。
这可以通过计算数据集中每一对变量之间关系的矩阵来实现。
结果是对称矩阵,被称为相关矩阵,因为主对角线上的值是1.0,每一列总与其自身完全相关。
Spearman相关
两个变量可能有非线性关系,那么这一关系强度可能随着变量分布变化。此外,这两个变量可能是非高斯分布。在这种情况下,Spearman相关系数可用来总结两个数据样本的关系强度。这个方法也能判断变量间的线性关系,不过检验效能稍弱(可能相关分数会比正常更低)。
与Pearson相关系数一样,Spearman相关系数用-1到1表示相关的范围,即从完全负相关到完全正相关。这些统计数据是用每个样本中值的相对秩计算出来的,而并非用样本本身的协方差和标准差。这是一种常用的非参数统计方法,例如,我们不假定数据分布为高斯分布时,我们就使用这种统计方法。
尽管假定为单调关系,但变量之间的线性关系没有被假定。用单调关系可以描述两个变量之间增加或减少的关系。
如果你不确定两个变量之间的分布和可能存在的关系,那么用Spearman相关系数很合适。用spearmanr() SciPy函数计算两个相同长度的数据样本的Spearman相关系数。我们可以计算出测试问题中两个变量间的相关。
下面列出了完整的示例。

运行这个示例,计算并打印出Spearman相关系数。
我们可以看到数据符合高斯分布且变量之间存在线性相关。然而,非参数秩次方法显示了变量间的高相关,相关为0.8。

与Pearson相关系数相同,Spearman相关系数可以成对计算数据集中的系数并得出相关矩阵。
扩展
本节列出了一些本教程的想法扩展,你可能希望进行深入探索。
用正、负相关生成你自己的数据集,并计算相关系数。
编写函数计算数据集的sqdz或寂寞的耳机相关矩阵。
建立一个标准的机器学习数据集,并计算所有实值变量对的相关系数。
总结
读完本教程,你明白了相关性是变量之间关系的统计概要,以及在不同类型的变量和关系中,如何计算它。
具体来说,你学会了:
如何通过计算协方差矩阵,总结两个或多个变量间的线性关系。
如何通过计算Pearson相关系数,总结两个变量间的线性关系。
如何通过计算Spearman相关系数,总结两个变量之间的单调关系。
快三稳赚10大技巧。
该系数返回的值在-1到1之间,表示相关的范围,即从完全负相关到完全正相关。0表示无相关。这个值必须被解释,通常低于-0.5或高于0.5的值表示显著的相关,其他范围的值则表示相关不显著。
pearsonr() SciPy函数可以计算两个相同长度的数据样本的Pearson相关系数。我们可以计算出测试问题中两个变量间的相关。
下面列出了完整的示例。
运行这个示例,计算并打印出Pearson相关系数。
我们可以看到这两个变量存在正相关关系,相关性为0.8。这意味着高相关,因为高于0.5且接近1.0。
可以用Pearson相关系数来评估两个以上变量间的关系。
这可以通过计算数据集中每一对变量之间关系的矩阵来实现。
结果是对称矩阵,被称为相关矩阵,因为主对角线上的值是1.0,每一列总与其自身完全相关。
Spearman相关
两个变量可能有非线性关系,那么这一关系强度可能随着变量分布变化。此外,这两个变量可能是非高斯分布。在这种情况下,Spearman相关系数可用来总结两个数据样本的关系强度。这个方法也能判断变量间的线性关系,不过检验效能稍弱(可能相关分数会比正常更低)。
与Pearson相关系数一样,Spearman相关系数用-1到1表示相关的范围,即从完全负相关到完全正相关。这些统计数据是用每个样本中值的相对秩计算出来的,而并非用样本本身的协方差和标准差。这是一种常用的非参数统计方法,例如,我们不假定数据分布为高斯分布时,我们就使用这种统计方法。
尽管假定为单调关系,但变量之间的线性关系没有被假定。用单调关系可以描述两个变量之间增加或减少的关系。
如果你不确定两个变量之间的分布和可能存在的关系,那么用Spearman相关系数很合适。用spearmanr() SciPy函数计算两个相同长度的数据样本的Spearman相关系数。我们可以计算出测试问题中两个变量间的相关。
下面列出了完整的示例。
运行这个示例,计算并打印出Spearman相关系数。
我们可以看到数据符合高斯分布且变量之间存在线性相关。然而,非参数秩次方法显示了变量间的高相关,相关为0.8。
与Pearson相关系数相同,Spearman相关系数可以成对计算数据集中的系数并得出相关矩阵。
扩展
本节列出了一些本教程的想法扩展,你可能希望进行深入探索。
用正、负相关生成你自己的数据集,并计算相关系数。
编写函数计算数据集的sqdz或寂寞的耳机相关矩阵。
建立一个标准的机器学习数据集,并计算所有实值变量对的相关系数。
总结
读完本教程,你明白了相关性是变量之间关系的统计概要,以及在不同类型的变量和关系中,如何计算它。
具体来说,你学会了:
如何通过计算协方差矩阵,总结两个或多个变量间的线性关系。
如何通过计算Pearson相关系数,总结两个变量间的线性关系。
如何通过计算Spearman相关系数,总结两个变量之间的单调关系。