
目录
- 1 RNN基础
-
- 1.1 what RNN?
- 1.2 why RNN?
- 1.3 how RNN?
-
- 1.3.1 隐含到隐含
- 1.3.2 输出到隐含
- 1.3.3 标签到隐含(导师驱动)
- 1.4 RNN的问题
- 2 Bi-RNN
- 3 gated RNN
-
- 3.1 LSTM
- 3.2 窥孔LSTM
- 3.3 耦合LSTM
- 3.4 GRU
- 4 目前存在的问题
- 参考
1 RNN基础
1.1 what RNN?
用于处理序列数据(可变长)的NN
1.2 why RNN?
在模型不同部分,共享参数
在几个时间步内,不需要分别学习权重
也能能泛化到不同长度的样本
为什么每个时间步用相同参数?
(1)减少参数数量
(2)实现可变长度
如果每步一个权重,不同长度的输入,权重的个数不一样,无法实现。
(3)泛化到新序列
如果每步一个权重,不能泛化到训练时没有见过的序列长度。
1.3 how RNN?
1.3.1 隐含到隐含

横向:时间轴
纵向:深度方向
1.3.2 输出到隐含

1.3.3 标签到隐含(导师驱动)

1.4 RNN的问题
(1)灾难性遗忘
记忆的时间长度有限
(2)梯度消失/爆炸
Jacobian矩阵
最大特征值<1:梯度呈指数级减小
最大特征值>1:梯度呈指数级增大
2 Bi-RNN

3 gated RNN
门控RNN
缓解RNN的两个问题,实现:
(1)长期记忆
(2)减缓梯度消失/爆炸
3.1 LSTM

3个门——遗忘门,输入门,输出门:

候选单元:
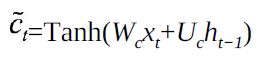
单元状态:长时记忆
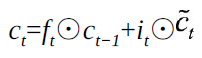
隐藏状态:短时记忆
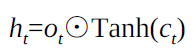
LSTM为什么用sigmoid和tanh两种激活?
这两类函数都是饱和的
sigmoid输出在0~1,可以实现门的开关
tanh输出在-1~1,数据中心化,且0附近的梯度比sigmoid大,收敛快
在LSTM中用tanh的直觉
LSTM为什么比RNN好?
LSTM有进有出,当前cell的信息c_tilda是通过inputgate控制后叠加的,而RNN是叠乘
因此,LSTM可以防止梯度消失和爆炸
在LSTM中加dropout:

3.2 窥孔LSTM
窥孔peehole:每个门接收单元状态的输入

3.3 耦合LSTM
耦合couple遗忘门、输入门

3.4 GRU

GRU和LSTM的区别?
(1)LSTM3个门,GRU两个门,LSTM有输出门,GRU没有
(2)所以,LSTM会把h包装一下传给下个单元,GRU直接将h传给下个单元


4 目前存在的问题
- 顺序计算抑制了并行化
- 没有对长期和短期依赖关系进行明确建模
- 位置之间的“距离”是线性的
参考
花书deep learning
https://ask.csdn.net/questions/699420
https://www.jianshu.com/p/9dc9f41f0b29
https://blog.csdn.net/u012223913/article/details/77724621