
网络由三个主要组件组成:
1)Backbone:在不同图像细粒度上聚合并形成图像特征的卷积神经网络。
2)Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。
3)output:对图像特征进行预测,生成边界框和并预测类别。
对于YOLOV5,无论是V5s,V5m,V5l还是V5x其Backbone,Neck和output一致。唯一的区别在与模型的深度和宽度设置。
总结构框架:

下面逐一解析:
1)Backbone
先代码,有个大概脉络:
# YOLOv5 backbone
backbone:# [from, number, module, args][[-1, 1, Focus, [64, 3]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, BottleneckCSP, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 9, BottleneckCSP, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, BottleneckCSP, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 1, SPP, [1024, [5, 9, 13]]],[-1, 3, BottleneckCSP, [1024, False]], # 9]
①Backbone第一层focus,从高分辨率图像中,周期性的抽出像素点重构到低分辨率图像中,即将图像相邻的四个位置进行堆叠,聚焦wh维度信息到c通道空间,提高每个点感受野,并减少原始信息的丢失,该模块的设计主要是减少计算量加快速度。
作者原话:Focus() module is designed for FLOPS reduction and speed increase, not mAP increase.
class Focus(nn.Module):# Focus wh information into c-spacedef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper(Focus, self).__init__()self.conv = Conv(c1 * 4, c2, k, s, p, g, act)def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))

在YOLOv5上的数据流向是:
YOLO V5默认3x640x640的输入,先复制四份,然后通过切片操作将这个四个图片切成了四个3x320x320的切片,接下来使用concat从深度上连接这四个切片,输出为12x320x320,之后再通过卷积核数为64的卷积层,生成64x320x320的输出,最后经过batch_borm 和leaky_relu将结果输入到下一个卷积层。
② Backbone第三层,BottleneckCSP模块。
BottleneckCSP模块主要包括Bottleneck和CSP两部分。
class BottleneckCSP(nn.Module):# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(BottleneckCSP, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)self.cv4 = Conv(2 * c_, c2, 1, 1)self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)self.act = nn.LeakyReLU(0.1, inplace=True)self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])def forward(self, x):y1 = self.cv3(self.m(self.cv1(x)))y2 = self.cv2(x)return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))

其中,在yolov5的模型配置文件中,有的BottleneckCSP模块配置存在False,而有的没有,如下:
[-1, 9, BottleneckCSP, [512]],
[-1, 3, BottleneckCSP, [512, False]], # 13
这里的False表示在这个BottleneckCSP中,不进行shortcut操作。
比如:
下图左图是无False的BottleneckCSP,右图是有False的BottleneckCSP。

④ SPP模块(空间金字塔池化模块), 分别采用5/9/13的最大池化,再进行concat融合,提高感受野。
SPP的输入是512x20x20,经过1×1的卷积层后输出256x20x20,然后经过并列的三个Maxpool进行下采样,将结果与其初始特征相加,输出1024x20x20,最后用512的卷积核将其恢复到512x20x20

2)Neck(PANet)
PANET基于 Mask R-CNN 和 FPN 框架,加强了信息传播,具有准确保留空间信息的能力,这有助于对像素进行适当的定位以形成掩模。
3)loss函数
边框回归:CIOU (GIOU的一种改进)
Objectness:GIOU

IOU:交并比
GIOU公式意思:先计算两个框的最小闭包区域面积Ac (通俗理解:同时包含了预测框和真实框的最小框的面积),再计算出IoU,再计算闭包区域Ac中不属于两个框的区域占闭包区域的比重,最后用IoU减去这个比重得到GIoU。
作为损失函数即:
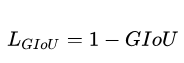
分类:BCE(交叉熵损失)
损失平衡:ciou=0.05,giou=1, bce=0.5
训练
1;环境
ubuntu ,python3.8, torch 1.6, torchvision 0.7
2;送到网络中训练的数据格式

每行5个浮点型数据,第一个为标签序号,第二个和第三个为目标归一化后的中心点坐标,第四个和第五个表示目标归一化后的长宽。
3:配置文件中参数说明
train_path: ./source_data/traindata #训练数据集
val_path: ./source_data/valdata #测试数据集convertor_path: ./convertor/chouyan #转换成训练模型所需要的的数据格式保存路径task_name: chouyan_s #任务名称,最后在这个文件夹下保存生成的模型names: ["xiangyan"] #类别名称gpu_ids: "2"
imgsz: 416
epochs: 50 #训练总共跑50个epoch
batch_size: 4
eval_interval: 5 #每5个epoch保存一次模型weights: ./weights/yolov5s.pt #预训练模型#weights: /data/dj/yolov5/work_dir/chouyan_s/2020-11-14/2020-11-14_15:17:32/epoch_15.pth # 在测试的时候,指定#测试的模型source: ./test_data/chouyan2/neg #测试的数据集路径,只需要图像output_pos: output_s_pos_neg #测试结果保存的路径,可根据自己需要保存
3:训练程序中需要注意的地方
1)配置参数
if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path') #如果预训练模型是#yolov5s,这里需要保持一致,最终训练的模型就是yolov5s版本parser.add_argument('--data', type=str, default='config.yaml', help='data.yaml path') # 配置文件名称parser.add_argument('--hyp', type=str, default='', help='hyp.yaml path (optional)')parser.add_argument('--epochs', type=int, default=300)parser.add_argument('--batch-size', type=int, default=16, help="Total batch size for all gpus.")parser.add_argument('--img-size', nargs='+', type=int, default=[416, 416], help='train,test sizes') #图像resize到的尺寸,可根据自己实际任务需求,改成640等,需要32的倍数parser.add_argument('--rect', action='store_true', help='rectangular training')parser.add_argument('--resume', nargs='?', const='get_last', default=False,help='resume from given path/to/last.pt, or most recent run if blank.')parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')parser.add_argument('--notest', action='store_true', help='only test final epoch')parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')parser.add_argument('--weights', type=str, default='', help='initial weights path')parser.add_argument('--name', default='', help='renames results.txt to results_name.txt if supplied')parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')opt = parser.parse_args()
2)模型存放路径
def init_logger(work_dir='./work_dir'): #在ubuntu下训练一定不要写成work_dir='.\work_dir',不然会找不到这个路径cur_time = datetime.datetime.now().strftime("%Y-%m-%d_%H:%M:%S")work_dir = os.path.join(work_dir, cur_time.split('_')[0], cur_time)mkdir_or_exist(os.path.abspath(work_dir))# loglog_file = os.path.join(work_dir, 'log.log')logger = get_root_logger(log_file)return logger, work_dir
4,最后直接运行python train.py 就可直接训练。
测试
直接运行python detect.py 就可直接训练。
YOLOv5三种模型比较

训练代码梳理
一:加载训练配置文件
二:Create model
① 导入模型配置文件
self.yaml = yaml.load(f, Loader=yaml.FullLoader)
② 根据模型配置文件,定义模型
if nc and nc != self.yaml[‘nc’]:
self.yaml[‘nc’] = nc # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch])
from n params module arguments 0 -1 1 8800 models.common.Focus [3, 80, 3] 1 -1 1 115520 models.common.Conv [80, 160, 3, 2] 2 -1 1 315680 models.common.BottleneckCSP [160, 160, 4] 3 -1 1 461440 models.common.Conv [160, 320, 3, 2] 4 -1 1 3311680 models.common.BottleneckCSP [320, 320, 12] 5 -1 1 1844480 models.common.Conv [320, 640, 3, 2] 6 -1 1 13228160 models.common.BottleneckCSP [640, 640, 12] 7 -1 1 7375360 models.common.Conv [640, 1280, 3, 2] 8 -1 1 4099840 models.common.SPP [1280, 1280, [5, 9, 13]] 9 -1 1 20087040 models.common.BottleneckCSP [1280, 1280, 4, False] 10 -1 1 820480 models.common.Conv [1280, 640, 1, 1] 11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 12 [-1, 6] 1 0 models.common.Concat [1] 13 -1 1 5435520 models.common.BottleneckCSP [1280, 640, 4, False] 14 -1 1 205440 models.common.Conv [640, 320, 1, 1] 15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 16 [-1, 4] 1 0 models.common.Concat [1] 17 -1 1 1360960 models.common.BottleneckCSP [640, 320, 4, False] 18 -1 1 922240 models.common.Conv [320, 320, 3, 2] 19 [-1, 14] 1 0 models.common.Concat [1] 20 -1 1 5025920 models.common.BottleneckCSP [640, 640, 4, False] 21 -1 1 3687680 models.common.Conv [640, 640, 3, 2] 22 [-1, 10] 1 0 models.common.Concat [1] 23 -1 1 20087040 models.common.BottleneckCSP [1280, 1280, 4, False] 24 [17, 20, 23] 1 40374 models.yolo.Detect [1, [[15.086, 10.896, 12.185, 27.484, 28.191, 13.015], [26.104, 23.376, 53.062, 15.104, 18.795, 51.715], [45.032, 25.534, 31.85, 40.063, 49.745, 47.505]], [320, 640, 1280]]
③ 获取前向输出
m = self.model[-1] # Detect()
从上面模型结构上就可以看到,yolov5把三个尺度的输出结果都存在最后一层,所以获取前向结果,直接取模型最后一层结果即可。
④ 将配置好的anchors根据[8,16,32]的尺度归一化。
m.anchors /= m.stride.view(-1, 1, 1) #m.stride=[8,16,32]
三:根据创建的模型结构,加载预训练模型参数
四:设置一些训练技巧:
①model, optimizer = amp.initialize(model, optimizer, opt_level=‘O1’, verbosity=0)
amp.initialize函数的作用不是提高模型精度或者训练速度,它是用来降低显存消耗。
主要看opt_level参数的配置,00相当于原始的单精度训练。01在大部分计算时采用半精度,但是所有的模型参数依然保持单精度,对于少数单精度较好的计算(如softmax)依然保持单精度。02相比于01,将模型参数也变为半精度。03基本等于最开始实验的全半精度的运算。值得一提的是,不论在优化过程中,模型是否采用半精度,保存下来的模型均为单精度模型,能够保证模型在其他应用中的正常使用。
② 学习率的调整方式
pytorch有3中调整学习率的策略:
1)有序调整:等间隔调整(Step),按需调整学习率(MultiStep),指数衰减调整(Exponential)和余弦退火CosineAnnealing
2)自适应调整: ReduceLROnPlateau
3)自定义调整: LambdaLR
③多GPU训练处理
model = torch.nn.DataParallel(model)
如果调用torch.nn.DataParallel,在设置GPU训练的时候,就一定需要设置2块或2块以上,如果只设置单卡训练就会报错。
④ 对预模型参数做平均操作,增加模型训练时的鲁棒性
ema = torch_utils.ModelEMA(model)
五:训练数据集和验证数据集处理
create_dataloader()
六:给模型设置一些参数
包括类别数量,类别名称,类别权重等
七:anchor设置
是否需要修改anchor:
check_anchors(dataset, model=model, thr=hyp[‘anchor_t’], imgsz=imgsz)
如果自己数据集anchor大小尺寸分布不像coco数据集那样丰富,比如:小目标检测,建议根据自己数据集去聚类一份新的anchor
# anchors:
# - [10,13, 16,30, 33,23] # P3/8
# - [30,61, 62,45, 59,119] # P4/16
# - [116,90, 156,198, 373,326] # P5/32
anchors:- [15.086,10.896,12.185,27.484,28.191,13.015] # P3/8- [26.104,23.376,53.062,15.104,18.795,51.715] # P4/16- [45.032,25.534,31.85,40.063,49.745,47.505] # P5/32直接将utils中的kmeans_anchor复制到本地,在本地运行即可。
kmean_anchors(path=‘E:projectsYOLO5datachouyan.yaml’, n=9, img_size=416, thr=8.0, gen=1000, verbose=True)
按照coco.yaml新建配置一个xxxx.yaml文件,里面设置好训练集路径;n=9,表示聚类9个点,这个不要改,img_size训练集图像大小,thr训练集目标长宽比例,因为我需要训练的目标是小细长条的形状,便将coco中的thr=4.0改成了8.0,增大目标长宽比。
八:训练
for epoch in range(start_epoch, epochs):...for i, (imgs, targets, paths, _) in enumerate(dataloader): #分批训练...imgs = imgs.to(device, non_blocking=True).float() / 255.0 #uint8 to float32...pred = model(imgs) #前向处理loss, loss_items = compute_loss(pred, targets.to(device), model) #计算loss...results, correct,maps, times = test.test(...) #验证集验证torch.save(...) #保存模型
loss梳理
1)前向处理结果:

8,16,32三个尺度的输出
② 计算loss
1)tcls, tbox, indices, anchors = build_targets(p, targets, model)
def build_targets(p, targets, model): #p:三个尺度的特征图; targets:标签信息,det.anchors:预测的anchors# Build targets for compute_loss(), input targets(image,class,x,y,w,h)det = model.module.model[-1] if type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel) else model.model[-1] # Detect() modulena, nt = det.na, targets.shape[0] # number of anchors, targetstcls, tbox, indices, anch = [], [], [], []gain = torch.ones(6, device=targets.device) # normalized to gridspace gain #shape[6]off = torch.tensor([[1, 0], [0, 1], [-1, 0], [0, -1]], device=targets.device).float() # overlap offsets #shape[4,2]at = torch.arange(na).view(na, 1).repeat(1, nt) # anchor tensor, same as .repeat_interleave(nt) #shape[3,1]g = 0.5 # offsetstyle = 'rect4'for i in range(det.nl):anchors = det.anchors[i] #分别获取每个尺度上的基于特征图大小的的anchor #shape[3,2]gain[2:] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain #shape[6] 获取每个尺度上预测的类别,已经类别置信度,目标cx,cy,w,h# Match targets to anchorsa, t, offsets = [], targets * gain, 0 #将gt的cx,cy,w,h换算到当前特征层对应的尺寸,以便和该层的anchor大小相对应if nt:r = t[None, :, 4:6] / anchors[:, None] # wh ratio #t_w,h/anchorsj = torch.max(r, 1. / r).max(2)[0] < model.hyp['anchor_t'] # compare #判断了r和1/r与model.hyp['anchor_t']的大小关系,返回bool值# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n) = wh_iou(anchors(3,2), gwh(n,2))a, t = at[j], t.repeat(na, 1, 1)[j] # filter #过滤掉长宽比大于阈值anchor_t的预测长宽组合# overlaps gxy = t[:, 2:4] # grid xy #获取gt的cx,cyz = torch.zeros_like(gxy)if style == 'rect2':j, k = ((gxy % 1. < g) & (gxy > 1.)).Ta, t = torch.cat((a, a[j], a[k]), 0), torch.cat((t, t[j], t[k]), 0)offsets = torch.cat((z, z[j] + off[0], z[k] + off[1]), 0) * gelif style == 'rect4':j, k = ((gxy % 1. < g) & (gxy > 1.)).Tl, m = ((gxy % 1. > (1 - g)) & (gxy < (gain[[2, 3]] - 1.))).Ta, t = torch.cat((a, a[j], a[k], a[l], a[m]), 0), torch.cat((t, t[j], t[k], t[l], t[m]), 0)offsets = torch.cat((z, z[j] + off[0], z[k] + off[1], z[l] + off[2], z[m] + off[3]), 0) * g# t.shape=[9,6] 即扩充了gt的数量,由原来3个anchor扩充到现在9个anchor,在每个gt中心点附近再扩充2个gt中心点# Defineb, c = t[:, :2].long().T # image, classgxy = t[:, 2:4] # grid xygwh = t[:, 4:6] # grid whgij = (gxy - offsets).long()gi, gj = gij.T # grid xy indices# Appendindices.append((b, a, gj, gi)) # image, anchor, grid indicestbox.append(torch.cat((gxy - gij, gwh), 1)) # boxanch.append(anchors[a]) # anchorstcls.append(c) # classreturn tcls, tbox, indices, anch训练过程中踩的坑:
现象:梯度nan
可能的原因:权重衰减严重,权重系数小,导致梯度过小,超出pytorch加速神器Apex存储范围,导致舍入误差。
现象:loss一直高居不下,召回率也是一直很低
原因:初始学习率设置过大。
为什么学习率对模型收敛影响这么大? 首先先梳理一下网络参数更新过程。
Pytorch 模型参数更新过程:
1,通过网络前向输出与真实标签之间的误差,得到loss。
2,通过loss.backward()完成误差的反向传播,通过pytorch的内在机制完成自动求导得到每个参数的梯度W_grad.
if mixed_precision:with amp.scale_loss(loss, optimizer) as scaled_loss:scaled_loss.backward()else:loss.backward()
正常的程序,得到梯度之后,就启动优化算法,对权重进行更新。但是yolov5中,使用梯度累计的trick,即
if ni % accumulate == 0:optimizer.step()optimizer.zero_grad()
就是,在计算出梯度之后,不是马上启动优化算法,而是继续下一个batch过来计算loss,再在原来梯度基础上,计算这一个batch的梯度,也就实现了多个batch的梯度积累成一个梯度,根据这个累计的梯度,去对模型参数更新,也就完成了一次模型迭代。
3,通过优化算法,对模型参数更新。
①优化过程:
优化算法的通用的公式是:
W_data=W_data+W_grad*lr
其中W_data为模型参数,W_grad为参数梯度,lr为学习率。
optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
pytorch框架,一般的优化算法中,都会对模型参数进行L2正则化的权重衰减处理,经过权值衰减处理后,输出的权重会变小,目的是为了防止过拟合。
@torch.no_grad()def step(self, closure=None):"""Performs a single optimization step.Arguments:closure (callable, optional): A closure that reevaluates the modeland returns the loss."""loss = Noneif closure is not None:with torch.enable_grad():loss = closure()for group in self.param_groups:weight_decay = group['weight_decay']momentum = group['momentum']dampening = group['dampening']nesterov = group['nesterov']for p in group['params']:if p.grad is None:continued_p = p.gradif weight_decay != 0:d_p = d_p.add(p, alpha=weight_decay) #权值L2正则化衰减if momentum != 0:param_state = self.state[p]if 'momentum_buffer' not in param_state:buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()else:buf = param_state['momentum_buffer']buf.mul_(momentum).add_(d_p, alpha=1 - dampening)if nesterov:d_p = d_p.add(buf, alpha=momentum)else:d_p = bufp.add_(d_p, alpha=-group['lr']) #权值更新return loss
② 模型参数更新:
optimizer.step()
③ 梯度归零。
optimizer.zero_grad()
一次梯度更新一次模型,下一轮模型的更新,需要下一轮新算出来的梯度。
4,对更新的模型参数均值处理
ema = torch_utils.ModelEMA(model) if rank in [-1, 0] else Noneema.update(model)
针对学习率优化的几个方式:
① Warmup
可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳
有助于保持模型深层的稳定性。
if ni <= nw:xi = [0, nw] # x interp# model.gr = np.interp(ni, xi, [0.0, 1.0]) # giou loss ratio (obj_loss = 1.0 or giou)accumulate = max(1, np.interp(ni, xi, [1, nbs / total_batch_size]).round())for j, x in enumerate(optimizer.param_groups):# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0x['lr'] = np.interp(ni, xi, [0.1 if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])if 'momentum' in x:x['momentum'] = np.interp(ni, xi, [0.9, hyp['momentum']])② 学习率调整方案
Pytorch 提供的学习率调整策略分为三大类:
a. 有序调整:等间隔调整(Step),按需调整学习率(MultiStep),指数衰减调整(Exponential)和 余弦退火CosineAnnealing。
b. 自适应调整:自适应调整学习率 ReduceLROnPlateau。
c. 自定义调整:自定义调整学习率 LambdaLR。