
librosa是python中用于 音乐 与 语音分析的库,主要用于提取音频文件的特征。官方文档
文章目录
- 一、安装
-
-
- 方法一
- 方法二
- 方法三
-
- 二、音频预处理(librosa.* 与 librosa.core.* 调用相同)
-
- (1)读取音频
-
- 将音频信号转化为单声道
- (2)使用IPython.display.Audio 直接在jupyter笔记本中播放音频
- (3)重采样
- (4)读取时长
- (5)读取采样率
- (6)librosa.clicks()
- (7)librosa.tone()
- (8)librosa.chirp()
- (9)librosa.zero_crossings() 过零率
- (10)librosa.autocorrelate有界自相关
- 三、可视化音频
-
- (1)波形包络图 librosa.display.waveplot
-
-
-
- 音频信号每一位分别对应一个采样点,其位数等于“采样率*音频时长(以秒为单位)”,记录了每个样本上音频的振幅信息.
-
-
- (2)可视化声(语)谱图 (spectrogram) librosa.display.specshow
- (3)librosa.display.camp() 从给定的数据中获取默认的颜色映射。
- (4)librosa.display.TimeFormatter() 时间轴的刻度格式化程序。
- (5)librosa.display.NoteFormatter() Notes的刻度格式。
- (6)librosa.display.LogHzFormatter() 用于对数频率的制表程序
- (7)librosa.display.ChromaFormatter() 色度轴的格式化程序
- (8)librosa.display.TonnetzFormatter() tonnetz轴的格式化程序
- 四、特征提取
-
- (1)过零率 librosa.feature.zero_crossing_rate()
- (2)librosa.feature.spectral
-
- ①频谱质心 librosa.feature.spectral centroid()
- ②声谱衰减 Spectral Roll-off
- ③librosa.feature.spectral_bandwidth() 谱带宽
- ④librosa.feature.spectral_contrast() 谱对比度
- ⑤librosa.feature.spectral_flatness() 频谱平坦度
- (3)梅尔频率倒谱系数 librosa.feature.mfcc()
- (4)librosa.feature.chroma
-
- ①色度频率 librosa.feature.chroma_stft()
- ②librosa.feature.chroma_cqt 常数Q色谱图
- ③librosa.feature.chroma_cens() 色谱能量归一化。
- (5)Mel scaled Spectrogram梅尔频谱
-
- Log-Mel Spectrogram
- (6)librosa.feature.rms() 谱的均方根能量(能量包络)
- (7)librosa.feature.poly_feature()
- (8)librosa.feature.tonnetz()
- [librosa | 系统实战(五~十七)](https://blog.csdn.net/qq_44250700/article/details/119956311)
- [librosa | 系统实战(十八~十九)写音频&音乐](https://blog.csdn.net/qq_44250700/article/details/119958423)
一、安装
方法一
pip install librisa
方法二
如果安装了Anaconda,可以通过conda命令安装:
conda install -c conda-forge librosa
方法三
source (一般在linux系统),直接使用源码安装,需要提前下载源码,即tar.gz文件
(https://github.com/librosa/librosa/releases/),通过下面命令安装:
tar xzf librosa-VERSION.tar.gzcd librosa-VERSION/python setup.py install
二、音频预处理(librosa.* 与 librosa.core.* 调用相同)
librosa.core 核心功能包括从磁盘加载音频、计算各种谱图表示以及各种常用的音乐分析工具,调用方法为librosa.core.*。
为了方便起见,这个子模块中的所有功能都可以直接从顶层librosa.*名称空间访问。
导包:
import librosa
import librosa.display# 一个用于音频可视化的API,这是建立在matplotlib之上的
import matplotlib.pyplot as plt
(1)读取音频
load an audio file as a floating point time series:
librosa.load(path, sr=22050, mono=True, offset=0.0, duration=None) #可以是WAV、Mp3等
参数:
path :音频文件的路径。
sr:采样率,是每秒传输的音频样本数,以Hz或kHz为单位。默认采样率为22050Hz(sr缺省或sr=None),高于该采样率的音频文件会被下采样,低于该采样率的文件会被上采样。
以44.1KHz重新采样:librosa.load(audio_path, sr=44100)
禁用重新采样(使用音频自身的采样率):librosa.load(audio_path, sr=None)
mono :bool值,表示是否将信号转换为单声道。mono=True为单声道,mono=False为stereo立体声
offset :float,在此时间之后开始阅读(以秒为单位)
duration:持续时间,float,仅加载这么多的音频(以秒为单位)
dtype:返回的音频信号值的格式,似乎只有float和float32
res_type:重采样的格式
返回:
y:音频时间序列,类型为numpy.ndarray
sr:音频的采样率,如果参数没有设置返回的是原始采样率
应用:
①读取wav文件。例:
import librosa
audio_path = 'D:/My life/Yellow.wav'#音频地址
librosa.load(audio_path, sr=44100)
②读取mp3文件。例:
import librosa
audio_path = 'D:/My life/music/some music/sweeter.mp3'#音频地址
librosa.load(audio_path, sr=44100)
读取mp3文件报错“raise NoBackendError()”原因:没有安装ffmpeg包。不能简单使用pip install ffmpeg,因为在anaconda的下的tensorflow环境根本就没用FFmpeg,这样导致无法找到ffdec.py下的指令来调出指令。
解决办法:只需cmd输入一行指令:conda install ffmpeg -c conda-forge
③查看是否为单声道:
y, sr = librosa.load(librosa.util.example_audio_file())y.shape#如果y.shape样式为(2,n)则是立体声,如果是(n,)则是单声道
将音频信号转化为单声道
librosa.to_mono(y)
④返回结果:
y , sr = librosa.load(audio_path)
print(type(y), type(sr))
#返回结果为:<class 'numpy.ndarray'> <class 'int'>
(2)使用IPython.display.Audio 直接在jupyter笔记本中播放音频
import IPython.display as ipd
ipd.Audio(audio_path)
应用:

(3)重采样
重新采样从orig_sr到target_sr的时间序列:
librosa.resample(y, orig_sr, target_sr, fix=True, scale=False)
参数:
y:音频时间序列。可以是单声道或立体声。
orig_sr:y的原始采样率
target_sr:目标采样率
fix:bool,调整重采样信号的长度。
scale:bool,缩放重新采样的信号,以使y和y_hat具有大约相等的总能量。
返回:
y_hat :重采样之后的音频数组
应用:
#原始音频采样率为48kHz,利用librosa库中的resample函数将这段音频下采样到16KHz。
import librosafile = 'D:/My life/music/some music/sweeter.mp3'
newFile = 'D:/My life/music/some music/sweeter_16k.wav' #应保存为.wav文件,否则会报错y, sr = librosa.load(file, sr=48000)
y_16k = librosa.resample(y,sr,16000)
soundfile.write(newFile, y_16k, 16000)
(4)读取时长
计算时间序列的的持续时间(以秒为单位):
librosa.get_duration(y=None, sr=22050, S=None, n_fft=2048, hop_length=512, center=True, filename=None)
参数:
y:音频时间序列
sr:y的音频采样率
S:STFT矩阵或任何STFT衍生的矩阵(例如,色谱图或梅尔频谱图)。根据频谱图输入计算的持续时间仅在达到帧分辨率之前才是准确的。如果需要高精度,则最好直接使用音频时间序列。
n_fft:S的FFT窗口大小
hop_length :S列之间的音频样本数
center :布尔值
如果为True,则S [:, t]的中心为y [t* hop_length]
如果为False,则S [:, t]从y[t * hop_length]开始
filename:如果提供,则所有其他参数都将被忽略,并且持续时间是直接从音频文件中计算得出的。
返回:
d :持续时间(以秒为单位)
应用:
import librosadef get_duration_mp3_and_wav(file_path): #获取mp3/wav音频文件时长duration = librosa.get_duration(filename=file_path)#如果提供filename,则所有其他参数都将被忽略,并且持续时间是直接从音频文件中计算得出的。return durationif __name__ == "__main__":file_path = 'D:/My life/music/some music/sweeter.mp3'duration = get_duration_mp3_and_wav(file_path)# mp3和wav均可print(f'duration = {duration}')#输出歌曲时长(单位为秒)
输出结果:
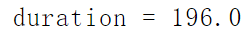
sweeter歌曲时长3分16秒,正是196秒。
(5)读取采样率
librosa.get_samplerate(path)
参数:
path :音频文件的路径
返回:
音频文件的采样率
(6)librosa.clicks()
在指定位置放置click信号,摘取想要的音频部分。
参数为:
times:在第几秒处点击(click),即摘取的开始时间位置,秒数为单位
frames:摘取的帧的索引值
sr:输出的采样率
hop_length:即步长,翻译为每帧之间的采样数
click_freq:摘取频率
click_duration:摘取的持续时间
click:摘取方式
length:输出的长度
返回值:
click_signal:摘取的信号合成
(7)librosa.tone()
生成一个tone信号,即一个简单的正弦波
(8)librosa.chirp()
生成一个chirp信号
(9)librosa.zero_crossings() 过零率
描述声音的明亮程度,声音越明亮,过零率越高。因为声音信号是波形,所以过零率越高,表示频率越高。
参数为:
y:信号值
threshold: -threshold <= y <= threshold 在这范围的值都算0
ref_magnitude:threshold的可缩放
pad:类似与卷积的pad,为0是valid zero-crossing.
zero_pos:
If True then the value 0 is interpreted as having positive sign.#0为正值
If False, then 0, -1, and +1 all have distinct signs.#各自有各自的意思
axis:维,沿着什么方向
返回值:
二值数据,如果是过零点返回true,不是则为false
可以通过np.nonzero(z)返回索引值
应用1:(以Pop_Therapy这首音乐为例,感兴趣的朋友可以去音乐软件上听听)
import soundfile
audio_path2 = 'D:/my life/music/Pop_Therapy.mp3'
y2, sr2 = librosa.load(audio_path2)
start = 0
duration = 3 #音频时长为5s
stop = start +duration
audio_dst = y2[start*sr2:stop*sr2]
soundfile.write('D:/my life/music/Pop_Therapy截取.wav', audio_dst, sr2) import IPython.display as ipd
dongda, sr = librosa.load('D:/my life/music/Pop_Therapy截取.wav')
ipd.Audio(dongda, rate=sr)

plt.figure(figsize=(14, 5))
librosa.display.waveplot(dongda, sr=sr)

zcrs_init = librosa.feature.zero_crossing_rate(dongda)# 画出音频波形和每一帧下的过零率
plt.figure(figsize=(14, 5))
zcrs_times = librosa.frames_to_time(np.arange(len(zcrs_init[0])), sr=sr, hop_length=512)
librosa.display.waveplot(dongda, sr=sr, alpha=0.7)
plt.plot(zcrs_times,zcrs_init[0], label='ZCR', lw=3, color='green')
plt.legend()

此处引用梁大贝茨“无痛入门音乐科技”中的话:我们会发现过零率高的区域恰巧对应了该“动打动动打”音频中“打”的部分,其实“动”是底鼓而“打”是小鼓的声音,底鼓声音的频率较低所以也听上去非常沉稳,而小鼓频率较高听上去“精神多了”,声音的频率高则其在单位时间内拥有更多波形周期,因此 单位时间内过零数会更多,那么过零率就更高。
音频最开始的“无声”区域,其实是有许多非常小数值的样本在界限0的周围转悠,所以也得到了较高的过零率。我们可以先给整个音频样本的数值都加个小小的常数,消除这些小数值对过零率计算的影响:
zcrs = librosa.feature.zero_crossing_rate(dongda + 0.0001)# 画出音频波形和每一帧的过零率(绿线)vs处理后得到的过零率(橙线)
plt.figure(figsize=(14, 5))
zcrs_times = librosa.frames_to_time(np.arange(len(zcrs[0])), sr=sr, hop_length=512)
librosa.display.waveplot(dongda, sr=sr, alpha=0.7)
plt.plot(zcrs_times,zcrs[0], label='Processed ZCR', lw=4, color='orange')
plt.plot(zcrs_times,zcrs_init[0], label='Initial ZCR', lw=2, alpha=0.5, color='green')
plt.legend()

用同样的方法绘制了钢琴曲《巴赫:小步舞曲》的前三秒(如下图),可以很明显看出没有明显的过零率起伏。

应用二:用钢琴弹出“C5 E5 G5 C6 E6 G6”,频率依次升高。

代码如下:
import librosa
import IPython.display as ipd
dongda, sr = librosa.load('D:/my life/music/频率.mp3')
ipd.Audio(dongda, rate=sr)import matplotlib.pyplot as plt
import librosa.display
plt.figure(figsize=(14, 5))
librosa.display.waveplot(dongda, sr=sr)

import numpy as np
import soundfile
zcrs_init = librosa.feature.zero_crossing_rate(dongda)# 画出音频波形和每一帧下的过零率
plt.figure(figsize=(14, 5))
zcrs_times = librosa.frames_to_time(np.arange(len(zcrs_init[0])), sr=sr, hop_length=512)
librosa.display.waveplot(dongda, sr=sr, alpha=0.7)
plt.plot(zcrs_times,zcrs_init[0], label='ZCR', lw=3, color='green')
plt.legend()

zcrs = librosa.feature.zero_crossing_rate(dongda + 0.0001)# 画出音频波形和每一帧的过零率(绿线)vs处理后得到的过零率(橙线)
plt.figure(figsize=(14, 5))
zcrs_times = librosa.frames_to_time(np.arange(len(zcrs[0])), sr=sr, hop_length=512)
librosa.display.waveplot(dongda, sr=sr, alpha=0.7)
plt.plot(zcrs_times,zcrs[0], label='Processed ZCR', lw=4, color='orange')
plt.plot(zcrs_times,zcrs_init[0], label='Initial ZCR', lw=2, alpha=0.5, color='green')
plt.legend()

可以看到随着频率的上升,过零率逐渐增大。
(10)librosa.autocorrelate有界自相关
自相关(autocorrelation)也叫序列相关,可以描述一个信号与其沿时间轴位移后的版本之间的相似度。
参数为:
y:信号值
max_size:要求自相关的长度
axis:沿着的维
返回值:
y关于max_size的自相关值
应用1:本实验所用音频是用“随身乐队”中的钢琴弹奏的 E5 音。
oboe_data, sr = librosa.load('D:/my life/music/E5.mp3')
ipd.Audio(oboe_data, rate=sr)

#假设已知音频中的音高在A0到C8之间即基频范围在:
f_low = 27.5
f_high = 4186.01#则对应的最小与最大k为:
k_high = sr/f_low # 22050/27.5 = 801.81
k_low = sr/f_high # 22050/4186.01 = 5.2675r = librosa.autocorrelate(oboe_data, max_size=int(k_high)) # int(k_high) = 801
r[:int(k_low)] = 0 # r[:5] = 0
# int是向下取整,即往数值小的方向取整
# 这里指算出平移距离为[5,801]时,分别对应的相似度r。
# 因为 信号 与 其延时间轴平移一个周期之后 最相似,因此找到相似度r最大时对应的平移距离,再根据平移距离推算出频率,就是所求信号的频率。# 画出自相关结果
plt.figure(figsize=(14, 5))
plt.plot(r)

#在以上结果中取纵轴数值最大处对应的横轴k的值,即为基频对应的时移参数:
k_fundamental = r.argmax()
print(k_fundamental)
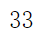
#基频为:
print("{} Hz".format(sr/k_fundamental))
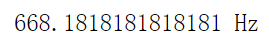
E5频率是659.25Hz,可以看出结果还是很接近的。
注:
Hz:频率f的单位,每秒钟振动一次为1Hz。
sr:采样率,也就是每秒钟采样的样本数。
k:每秒钟所采的样本点数。
记住公式:
①sr = k / s
②f = 1/T,当T设定为秒时,f = 1/s
则sr / f = sr * s = k。
③sr / k = f
应用2:本实验所用音频是用“随身乐队”中的钢琴弹奏的 C2 音。
注:当程序计算结果与实际情况不符时,有可能是输入的音频文件不准确,比如有杂音等。
如图所示,当笔者录C2音时,录入了一段空白音,所以实验结果出现了偏差。当去掉空白部分,将调整之后的音频作为输入,发现计算结果就正常了。
原始音频文件的波形图:

导入音频:
import librosa
import matplotlib.pyplot as pltC2, sr = librosa.load('D:/my life/music/C2.mp3')
确定音频文件长度:
len(C2)/sr # 确定
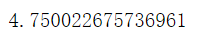
确定空白音频的结束点:
for i in C2:if i != 0: print(C2.index(i)/sr)

…
由此可知:C2音频非零起始点约为1.59秒,结束点约为4.75秒。
取2秒到4秒之间的音频片段作为新的输入:
# 音频预处理:对音频进行处理
start = 2
duration = 2 #音频时长为3s
stop = start +duration
audio_dst = C2[start*sr:stop*sr]
soundfile.write('D:/my life/music/C2_cut.wav', audio_dst, sr)
C2_cut, sr = librosa.load('D:/my life/music/C2_cut.wav')
画出自相关:
#假设已知音频中的音高在A0到C8之间即基频范围在:
f_low = 27.5
f_high = 4186.01#则对应的最小与最大k为:
k_high = sr/f_low # 22050/27.5 = 801.81
k_low = sr/f_high # 22050/4186.01 = 5.2675r = librosa.autocorrelate(C2_cut, max_size=int(k_high)) # int(k_high) = 801
r[:int(k_low)] = 0 # r[:5] = 0# 画出自相关结果
plt.figure(figsize=(14, 5))
plt.plot(r)

#在以上结果中取纵轴数值最大处对应的横轴k的值,即为基频对应的时移参数:
k_fundamental = r.argmax()
print(k_fundamental)

#基频为:
print("{} Hz".format(sr/k_fundamental))
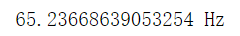
查阅下表可知:C2频率为65.406,可知,计算结果是准确的。

三、可视化音频
librosa.display. #使用matplotlib的可视化和显示例程。
错误:有import librosa,但是报错:AttributeError: module 'librosa' has no attribute 'display'
解决办法:因为librosa.display需要显示声明。加上import librosa.display即可。
(1)波形包络图 librosa.display.waveplot
包络图定义:
在音频或信号领域,可以简单地将 包络线 理解为 描述音量变化的曲线。它是一条将每个局部的峰值连接起来的曲线。
绘制波形的幅度包络线librosa.display.waveplot:
librosa.display.waveplot(y, sr=22050, x_axis='time', offset=0.0, ax=None)
参数:
y:音频时间序列
sr:y的采样率
x_axis:str {‘time’,‘off’,‘none’}或None,如果为“时间”,则在x轴上给定时间刻度线。
offset:水平偏移(以秒为单位)开始波形图
音频信号每一位分别对应一个采样点,其位数等于“采样率*音频时长(以秒为单位)”,记录了每个样本上音频的振幅信息.
应用:
import matplotlib.pyplot as plt
import librosa.display
plt.figure(figsize=(14, 5))#画布尺寸
librosa.display.waveplot(y, sr=sr)
#以韩语歌曲 sweeter 为例:

能量包络见:librosa.feature.rms() 谱的均方根能量
(2)可视化声(语)谱图 (spectrogram) librosa.display.specshow
声谱图,又称语谱图,是声音或其他信号的频率随时间变化时的频谱(spectrum)的一种直观表示,是“声纹”。每帧语音对应一个频谱,频谱表示频率与能量的关系。语谱图是三维的,第一维横轴是时间,第二维纵轴是频率,第三维由每点的强度或颜色表示特定时间、特定频率的幅度…当数据以三维图形表示时,可称其为瀑布图(waterfalls)(长得挺像瀑布的)。
显示频谱图 librosa.display.specshow:
librosa.display.specshow(data, x_axis=None, y_axis=None, sr=22050, hop_length=512)
参数:
data:要显示的矩阵 #如幅度谱、功率谱等
x_axis :x轴的范围
x_axis='time',表示横轴为音频的时间y_axis :y轴的频率类型(单位均为
Hz)
y_axis='hz',表示纵轴范围为音频的所有频率,单位是Hzy_axis='mel',表示纵轴频率由mel标度决定,单位是Hzy_axis='log',表示纵轴频率以对数刻度显示,单位是Hzsr :采样率
hop_length :帧移
频谱图有三种:
- 线性振幅谱、
- 对数振幅谱(对数振幅谱中各谱线的振幅都作了对数计算,所以其纵坐标的单位是dB(分贝)。这个变换的目的是使那些振幅较低的成分相得以拉高,以便观察掩盖在低幅噪声中的周期信号))、
- 自功率谱。
频率类型
‘linear’,‘fft’,‘hz’:频率范围由FFT窗口和采样率确定‘log’:频谱以对数刻度显示‘mel’:频率由mel标度决定所有频率类型均以Hz为单位绘制
时间类型
time:标记以毫秒,秒,分钟或小时显示。值以秒为单位绘制。
s:标记显示为秒。
ms:标记以毫秒为单位显示。
应用:
①data为幅度谱时(取绝对值得到的是幅度谱):
A = librosa.stft(y)
Adb = librosa.amplitude_to_db(abs(A))plt.figure(figsize=(14, 5))
librosa.display.specshow(Adb, sr=sr, x_axis='time', y_axis='hz')#纵轴表示频率(从0到20kHz),横轴表示剪辑的时间。
plt.colorbar()
关于colorbar点击此处学习

由于频谱集中在底部,声音的很多特性是隐藏在低频信息中的,可以将频率轴转换为对数轴,使频谱充满整个纵轴。同时在做DCT变换的时候可以把频谱的包络和细节区分开。
librosa.display.specshow(Adb, sr=sr, x_axis='time', y_axis='log')
plt.figure(figsize=(14, 5))
plt.colorbar()

②data为功率谱时:(取平方值得到的是功率谱)
A = librosa.stft(y)
Pdb = librosa.power_to_db(abs(A) ** 2)
librosa.display.specshow(Pdb, sr=sr, y_axis='log') # 从波形获取功率谱图
plt.figure(figsize=(14, 5))
librosa.display.specshow(Pdb, sr=sr, x_axis='time', y_axis='hz')
plt.colorbar()
(3)librosa.display.camp() 从给定的数据中获取默认的颜色映射。
(4)librosa.display.TimeFormatter() 时间轴的刻度格式化程序。
(5)librosa.display.NoteFormatter() Notes的刻度格式。
(6)librosa.display.LogHzFormatter() 用于对数频率的制表程序
(7)librosa.display.ChromaFormatter() 色度轴的格式化程序
(8)librosa.display.TonnetzFormatter() tonnetz轴的格式化程序
四、特征提取
特征提取和操作。这包括低层次特征提取,如彩色公音、伪常量q(对数频率)变换、Mel光谱图、MFCC和调优估计。此外,还提供了特性操作方法,如delta特性、内存嵌入和事件同步特性对齐。
librosa.feature.
(1)过零率 librosa.feature.zero_crossing_rate()
每帧语音信号从正变为负或从负变为正的次数。这个特征已在语音识别和音乐信息检索领域得到广泛使用,通常对类似金属、摇滚等高冲击性的声音的具有更高的价值。
计算音频时间序列的过零率:
librosa.feature.zero_crossing_rate(y, frame_length = 2048, hop_length = 512, center = True)
参数:
y:音频时间序列
frame_length :帧长
hop_length:帧移
center:bool,如果为True,则通过填充y的边缘来使帧居中。
返回:
zcr:zcr[0,i]是第i帧中的过零率
应用:
# 加载音频
y, sr = librosa.load('D:My lifemusicsome music/sweeter.mp3')
# Zooming in
n0 = 9000
n1 = 9100
plt.figure(figsize=(14, 5))
plt.plot(y[n0:n1])
plt.grid()#网格#用librosa验证:librosa.feature.zero_crossing_rate(y, frame_length = 2048, hop_length = 512, center = True)
zero_crossings = librosa.zero_crossings(x[n0:n1], pad=False)
print(sum(zero_crossings)) #过零点个数spectral_centroids = librosa.feature.spectral_centroid(x, sr=sr)[0]#质心
print(spectral_centroids.shape)librosa.feature.zero_crossing_rate(y)

(2)librosa.feature.spectral
①频谱质心 librosa.feature.spectral centroid()
指声音的“质心”,并按照声音频率的加权平均值来加以计算。假设现有两首歌曲,一首是蓝调歌曲,另一首是金属歌曲。现在,与同等长度的蓝调歌曲相比,金属歌曲在接近尾声位置的频率更高。所以蓝调歌曲的频谱质心会在频谱偏中间的位置,而金属歌曲的频谱质心则靠近频谱末端。
计算信号中每帧的光谱质心librosa.feature.spectral_centroid
应用:
# 加载音频
y, sr = librosa.load('D:My lifemusicsome music/sweeter.mp3')
# Computing the time variable for visualization
frames = range(len(spectral_centroids))
t = librosa.frames_to_time(frames)
# Normalising the spectral centroid for visualisation
import sklearn
def normalize(x, axis=0):return sklearn.preprocessing.minmax_scale(x, axis=axis)
#Plotting the Spectral Centroid along the waveform
librosa.display.waveplot(x, sr=sr, alpha=0.4)
plt.plot(t, normalize(spectral_centroids), color='r')

audio, sr = librosa.load('D:/my life/music/concat.wav')
D = librosa.stft(audio, n_fft=2048, hop_length=512)
magnitude, phase = librosa.magphase(D)
cent = librosa.feature.spectral_centroid(y=audio, sr=sr)
plt.figure(figsize=(15,10))# 画出音频数据在时域上的波形图
ax1 = plt.subplot(2,1,1)
librosa.display.waveplot(audio, sr, alpha=0.8)
plt.title('audio data')# 画出STFT后的功率谱(以dB为单位)以及频谱质心随时间的变化
ax2 = plt.subplot(2,1,2, sharex=ax1)
librosa.display.specshow(librosa.amplitude_to_db(magnitude, ref=np.max), sr=sr, y_axis='linear', x_axis='time')
cent_times = librosa.frames_to_time(np.arange(len(cent[0])), sr=sr, hop_length=512)
plt.plot(cent_times, cent[0], label='Spectral Centroid', lw=4, color='orange')
plt.legend()
plt.title('STFT spectrogram & Spectral Centroid')
笔者用电子音乐软件中的三种音色“八音盒、管风琴、原声钢琴”弹出了C5 D5 E5 C6 C5D5E5C6。频谱如下图所示。

从图中可以看出“管风琴”的频谱质心最高,这与主管听感一致(即管风琴音色最明亮)。从时域波形也可以看出,三种音色的波形图均不同。
②声谱衰减 Spectral Roll-off
是信号形状的度量。计算信号中每帧的滚降系数librosa.feature.spectral_rolloff:
应用:
spectral_rolloff = librosa.feature.spectral_rolloff(x+0.01, sr=sr)[0]
librosa.display.waveplot(x, sr=sr, alpha=0.4)
plt.plot(t, normalize(spectral_rolloff), color='r')

③librosa.feature.spectral_bandwidth() 谱带宽
④librosa.feature.spectral_contrast() 谱对比度
⑤librosa.feature.spectral_flatness() 频谱平坦度
(3)梅尔频率倒谱系数 librosa.feature.mfcc()
Mel-frequency cepstral coefficients (MFCC)。根据人耳的听觉特性:人耳对不同声波有不同的听觉敏感度,对200Hz~000Hz的语音信号最敏感。MFCC是在Mel幅度频率域提取出来的倒谱系数,描述了人耳的非线性特征。频率的关系可以表示为:Mel(f) = 2395 * lg(1 + f/700)。

时域上的语音信号经过:
①采样(一秒中采样N次。把一秒分成N帧,并且相邻两帧有overlap的部分,这可以保证声音信号的连续性)、
②傅里叶变换 转化成 频域信号,转化成能量谱。
对于低频成分敏感程度高,对于高频成分敏感程度低。

MFCCs可以准确描述声音功率谱包络(这个包络显示了声道形状)的特征,在自动语音识别和说话人识别中有着广泛使用。在librosa中,提取MFCC特征只需要一个函数:
librosa.feature.mfcc(y=None, sr=22050, S=None, n_mfcc=20, dct_type=2, norm='ortho', n_fft=N_FFT,hop_length=int(N_FFT/4)**kwargs)
参数:
y:音频数据。np.ndarray [shape=(n,)] 或 None
sr:y的采样率。number > 0 [scalar]
S:对数功能梅尔谱图。np.ndarray [shape=(d, t)] or None
n_mfcc:要返回的MFCC数量。 int > 0 [scalar]
dct_type:离散余弦变换(DCT)类型。默认情况下,使用DCT类型2。None, or {1, 2, 3}
norm: None or ‘ortho’ 规范。如果dct_type为2或3,则设置norm =’ortho’使用正交DCT基础。标准化不支持dct_type = 1。
n_fft:返回的mfcc数据维数,默认为13维。#获得N_FFT的长度N_FFT=getNearestLen(0.25,sr);print(“N_FFT:” , N_FFT)
hop_length:帧移
lifter: 如果 lifter>0, 提升倒谱滤波。设置lifter >= 2 * n_mfcc强调高阶系数。随着lifter的增加,权重系数近似为线性。
kwargs: 额外的关键参数。参数melspectrogram,如果按时间序列输入操作
返回:
M:np.ndarray [shape=(n_mfcc, t)] 。 MFCC序列
librosa.feature.mfcc函数内部:
# Mel spectrogram and MFCCs
def mfcc(y=None, sr=22050, S=None, n_mfcc=20, **kwargs):if S is None:S = logamplitude(melspectrogram(y=y, sr=sr, **kwargs))return np.dot(filters.dct(n_mfcc, S.shape[0]), S)
#可以看出,如果只给定原始的时域信号(即S参数为None),librosa会先通过melspectrogram()函数先提取时域信号y的梅尔频谱,存放到S中,
#再通过filters.dct()函数做dct变换得到y的梅尔倒谱系数。
应用:
import librosa
y, sr = librosa.load('D:/My life/music/some music/sweeter.mp3', sr=None)
mfccs = librosa.feature.mfcc(y, sr)
print (mfccs.shape)
librosa.display.specshow(mfccs, sr=sr, x_axis='time')#Displaying the MFCCs

钢琴音C2对应的语谱图:
import librosa
import matplotlib.pyplot as plt
C2_cut, sr = librosa.load('D:/my life/music/C2_cut.wav')
mfccs = librosa.feature.mfcc(C2_cut, sr)
import librosa.display
librosa.display.specshow(mfccs, sr=sr, x_axis='time',hop_length=512)#Displaying the MFCCs

sklearn.preprocessing.scale(mfccs, axis=1,with_mean=True, with_std=True)
作用:数据标准化
公式:(X-X_mean)/X_std 计算时对每个属性/每列分别进行。
原理:得到的结果是,对每个属性/每列来说所有数据都聚集在0附近,方差值为1。
参数:
X:待处理的数组
axis:表示处理哪个维度,0表示处理横向的数据(行), 1表示处理纵向的数据(列)
with_mean:默认为true,表示使均值为0
with_std:默认为true,表示使标准差为1
#执行特征缩放,使数据标准化,使得每个系数维度具有接近零的均值和单位方差:
import sklearn
mfccs = sklearn.preprocessing.scale(mfccs, axis=1,with_mean=True, with_std=True)
print(mfccs.mean(axis=1))
print(mfccs.var(axis=1))
librosa.display.specshow(mfccs, sr=sr, x_axis='time')


“MFCC特征提取工程流程图如下:???
导入音频文件
FrameBlocking 分帧
Windowing 对每帧进行加窗
FFT #FFT变换的作用是提取声音频谱信息,即将时域序列转换到频域表示,得到一个复数二维数组,横轴表示时间轴,每个点代表一帧,纵轴表示频率轴
Mel-frequency-Wrapping #Mel滤波的作用是将声音转换到Mel域,使其更符合人耳听觉特性,这步是对频率轴进行操作,和时间轴无关
Cepstrum
为了得到更加丰富的信息,沿时间轴做一阶偏微分,得到delta信息,做两次偏微分就得到delta-delta信息。
为什么要使用mel特征提取?
由于音频存在噪音,且有效数据没有很好地凸显出来,因此音频数据如果直接拿来做自动语音识别效果会非常差。使用mel特征提取可以将音频数据里有效信息进行提取、无用信息进行过滤,其原理是模拟人耳构造,对音频进行滤波,处理过后的数据再用来做自动语音识别效果会有显著提升。
Mel频率是基于人耳听觉特性提出来的,它与Hz频率成非线性对应关系。Mel频率倒谱系数(MFCC)则是利用它们之间的这种关系,计算得到的Hz频谱特征。
用录音设备录制一段模拟语音信号后,经由自定的取样频率(如8000 Hz、16000 Hz等)采样后转换(A/D)为数字语音信号。由于在时域(time domain)上语音信号的波形变化相当快速、不易观察,因此一般都会在频域(frequency domain)上来观察,其频谱是随着时间而缓慢变化的,因此通常可以假设在一较短时间中,其语音信号的特性是稳定的,通常我们定义这个较短时间为一帧(frame),根据人的语音的音调周期值的变化,一般取10~20ms继续阅读这篇文章。
MFCC特征的提取流程
音频信号(audio signal)是在时间,幅度和频率上的三维信号。声波有三个重要的参数:频率ω0,幅度An和相位ψ n。从频域角度来看,音频信号就是不同频率、相位和波幅的信号叠加。人类对声音的敏感区间在4000Hz左右,如果采样频率达到2*4000=8000Hz左右,原始信号的中的信息对于普通人而言是完美保留。”参考资料
Librosa库提取MFCC特征过程的原码解析
(4)librosa.feature.chroma
①色度频率 librosa.feature.chroma_stft()
色度频率是音乐音频有趣且强大的表示,其中整个频谱被投影到12个区间,代表音乐八度音的12个不同的半音(或色度)。librosa.feature.chroma_stft 用于计算。
x, sr = librosa.load('D:My lifemusicsome music/sweeter.mp3')
hop_length = 512
chromagram = librosa.feature.chroma_stft(x, sr=sr, hop_length=hop_length)
plt.figure(figsize=(15, 5))
librosa.display.specshow(chromagram, x_axis='time', y_axis='chroma', hop_length=hop_length, cmap='coolwarm')

从stft的结果计算色谱图
应用1:
x, sr = librosa.load('D:/My life/music/E5.mp3')hop_length = 512
chromagram = librosa.feature.chroma_stft(x, sr=sr, hop_length=hop_length)
plt.figure(figsize=(15, 5))
librosa.display.specshow(chromagram, x_axis='time', y_axis='chroma', hop_length=hop_length, cmap='coolwarm')

可以看出:E所对应的那一行是深红色,而音频所对应的音正是E5。因此识别是准确的。
应用2:
x, sr = librosa.load('D:/My life/music/C2.mp3')hop_length = 512
chromagram = librosa.feature.chroma_stft(x, sr=sr, hop_length=hop_length)
plt.figure(figsize=(15, 5))
librosa.display.specshow(chromagram, x_axis='time', y_axis='chroma', hop_length=hop_length, cmap='coolwarm')

可以看出:C所对应的那一行是深红色,而音频所对应的音正是C2。因此识别是准确的。
思考:从应用1和应用2均可看出,在标注音高之前有一段空白,这是因为原始音频在开始的一秒多存在空白时长。但是当笔者尝试将空白时长去除,再进行色度估计时,发现结果并不准确。具体原因还没找到,有待进一步实验。
②librosa.feature.chroma_cqt 常数Q色谱图
③librosa.feature.chroma_cens() 色谱能量归一化。
(5)Mel scaled Spectrogram梅尔频谱
librosa.feature.melspectrogram(y=None, sr=22050, S=None, n_fft=2048, hop_length=512, win_length=None, window='hann',center=True, pad_mode='reflect', power=2.0,**kwargs)
如果提供了频谱图输入S,则通过mel_f.dot(S)将其直接映射到mel_f上。
如果提供了时间序列输入y,sr,则首先计算其幅值频谱S,然后通过mel_f.dot(S ** power)将其映射到mel scale上 。默认情况下,power= 2在功率谱上运行。
参数:
y:音频时间序列
sr:采样率
S:频谱
n_fft:FFT窗口的长度
hop_length:帧移
win_length:窗口的长度为win_length,默认win_length = n_fft
window:字符串,元组,数字,函数或shape =(n_fft, )
窗口规范(字符串,元组或数字);看到scipy.signal.get_window
窗口函数,例如 scipy.signal.hanning
长度为n_fft的向量或数组
center:bool
如果为True,则填充信号y,以使帧 t以y [t * hop_length]为中心。
如果为False,则帧t从y [t * hop_length]开始
power:幅度谱的指数。例如1代表能量,2代表功率,等等
n_mels:滤波器组的个数 1288
fmax:最高频率
返回:
Mel频谱shape=(n_mels, t)
应用:
import librosa.display
import numpy as np
import matplotlib.pyplot as plt
y, sr = librosa.load('D:/My life/music/some music/sweeter.mp3')
方法一:使用时间序列求Mel频谱
print(librosa.feature.melspectrogram(y=y, sr=sr))
方法二:使用stft频谱求Mel频谱
D = np.abs(librosa.stft(y)) ** 2 # stft频谱
S = librosa.feature.melspectrogram(S=D) # 使用stft频谱求Mel频谱
plt.figure(figsize=(10, 4))
librosa.display.specshow(librosa.power_to_db(S, ref=np.max),y_axis='mel', fmax=8000, x_axis='time')
plt.colorbar(format='%+2.0f dB')
plt.title('Mel spectrogram')
plt.tight_layout()
plt.show()

解决特征融合问题:采用封装好的函数进行mfcc提取,我们得到的是一个经过分帧加窗及其一系列处理后的数据,要想在每一帧的mfcc后面添加其他特征首先要得到分帧的参数设置,然后对待融合特征采用相同的分帧机制,才能保证二者的融合是在相同帧的情况下进行的。例如我们要对mfcc特征与短时能量特征进行融合,我们在提取二者过程中要保证其分帧方式相同,然后对求得特征进行拼接。mfcc与能量的特征融合代码如下:
import librosa
import matplotlib.pyplot as plt
import numpy as nppath='D:/My life/music/some music/sweeter.mp3' # 声音文件绝对路径
y,sr=librosa.load(path,None) # 以原采样频率读取声音文件数据,并返回该数据及其采样频率
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=60,n_fft=1024, hop_length=512,fmax=16000)
mfcc=librosa.feature.mfcc(y, sr, S=librosa.power_to_db(S),n_mfcc=40) # 提取mfcc系数
stft_coff=abs(librosa.stft(y,1024,512,1024)) #分帧然后求短时傅里叶变换,分帧参数与对数能量梅尔滤波器组参数设置要相同
energy = np.sum(np.square(stft_coff),0) #求每一帧的平均能量
MFCC_Energy = np.vstack((mfcc,energy)) # 将每一帧的MFCC与短时能量拼接在一起
Log-Mel Spectrogram
是目前在语音识别和环境声音识别中很常用的一个特征,由于CNN在处理图像上展现了强大的能力,使得音频信号的频谱图特征的使用愈加广泛,甚至比MFCC使用的更多。
import librosa
y, sr = librosa.load('D:/My life/music/some music/sweeter.mp3', sr=None)
melspec = librosa.feature.melspectrogram(y, sr, n_fft=1024, hop_length=512, n_mels=128)#提取 mel spectrogram feature
logmelspec = librosa.amplitude_to_db(melspec) # 转换到对数刻度
print(logmelspec.shape) # (128, 65)
可见:
Log-Mel Spectrogram特征是二维数组的形式,128表示Mel频率的维度(频域),65为时间帧长度(时域)。
所以Log-Mel Spectrogram特征是音频信号的时频表示特征。
其中:
n_fft指的是窗的大小,这里为1024;
hop_length表示相邻窗之间的距离,这里为512,也就是相邻窗之间有50%的overlap;
n_mels为mel bands的数量,这里设为128。
(6)librosa.feature.rms() 谱的均方根能量(能量包络)
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
# 加载音频
audio_data, sr = librosa.load('D:/my life/music/Emotional.mp3', sr=None)# 调用librosa中的rmse直接对音频每个长度为2048的帧进行计算得到均方根能量
rmse = librosa.feature.rms(audio_data, frame_length=2048, hop_length=512)# 画出音频波形及均方根能量随时间的变化
plt.figure(figsize=(10,5))
librosa.display.waveplot(audio_data, sr, alpha=0.8)
times = librosa.frames_to_time(np.arange(len(rmse.T)), sr=sr, hop_length=512)
plt.plot(times, rmse.T, label='RMS Energy')
plt.legend(loc='best')

(7)librosa.feature.poly_feature()
求一个n阶多项式与谱图列的拟合系数
(8)librosa.feature.tonnetz()
计算色调质心特征(tonnetz)
librosa | 系统实战(五~十七)
librosa | 系统实战(十八~十九)写音频&音乐
参考资料:
深度学习在音频信号处理领域中的进展(截止至2019年5月)
Librosa的城市声音分类-棘手的交叉验证
使用谱减法对语音信号进行降噪(librosa),C#使用Speex
声音领域的算法库一般有librosa、essentia、torchaudio、深度学习等
excel 棒球数据游戏_使用librosa的棒球应用的音频发作检测数据准备